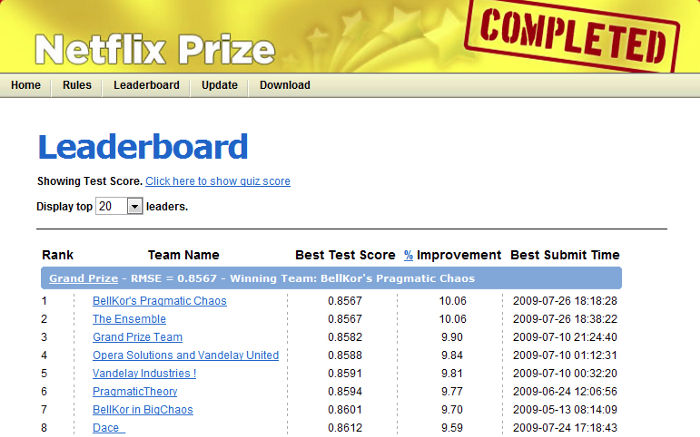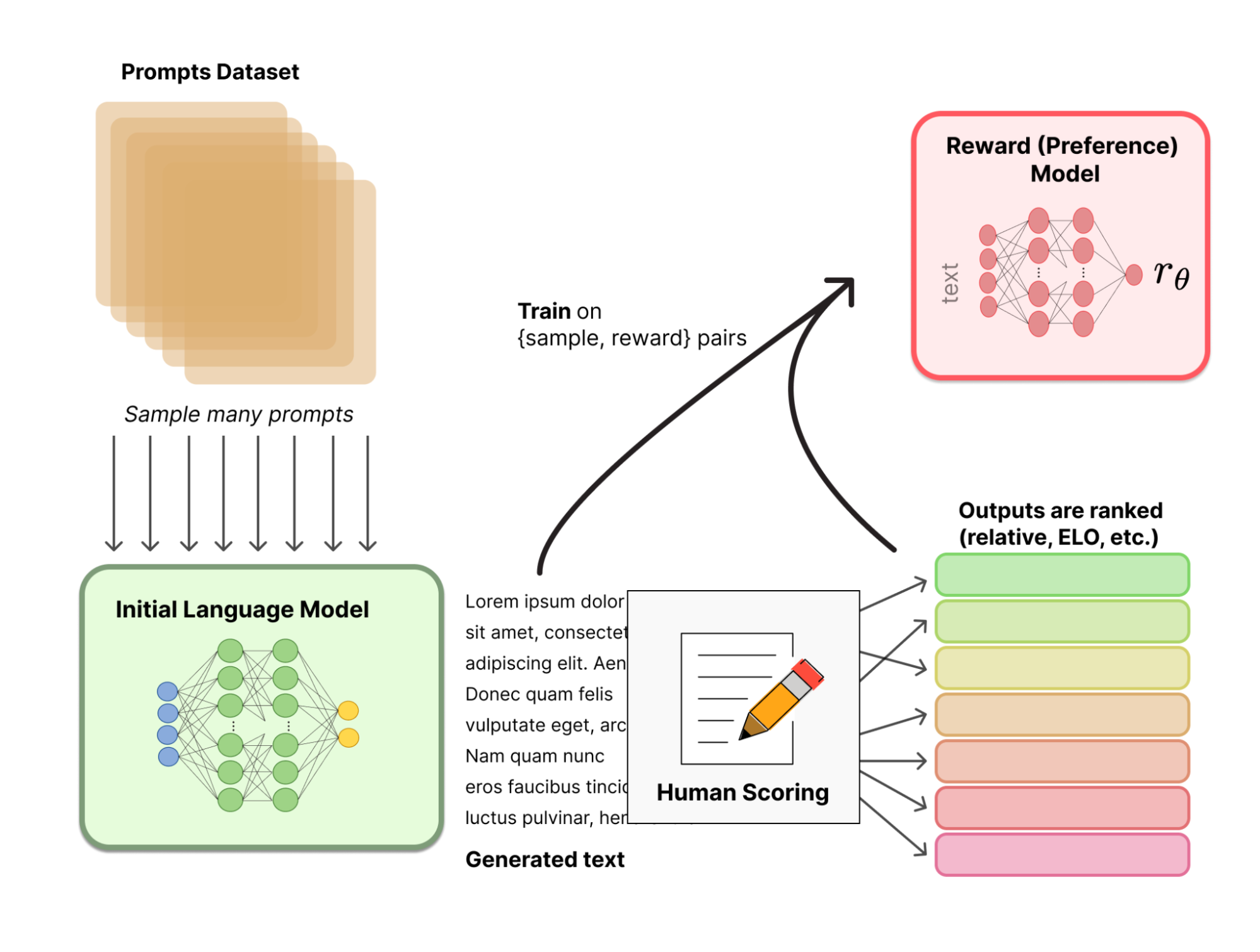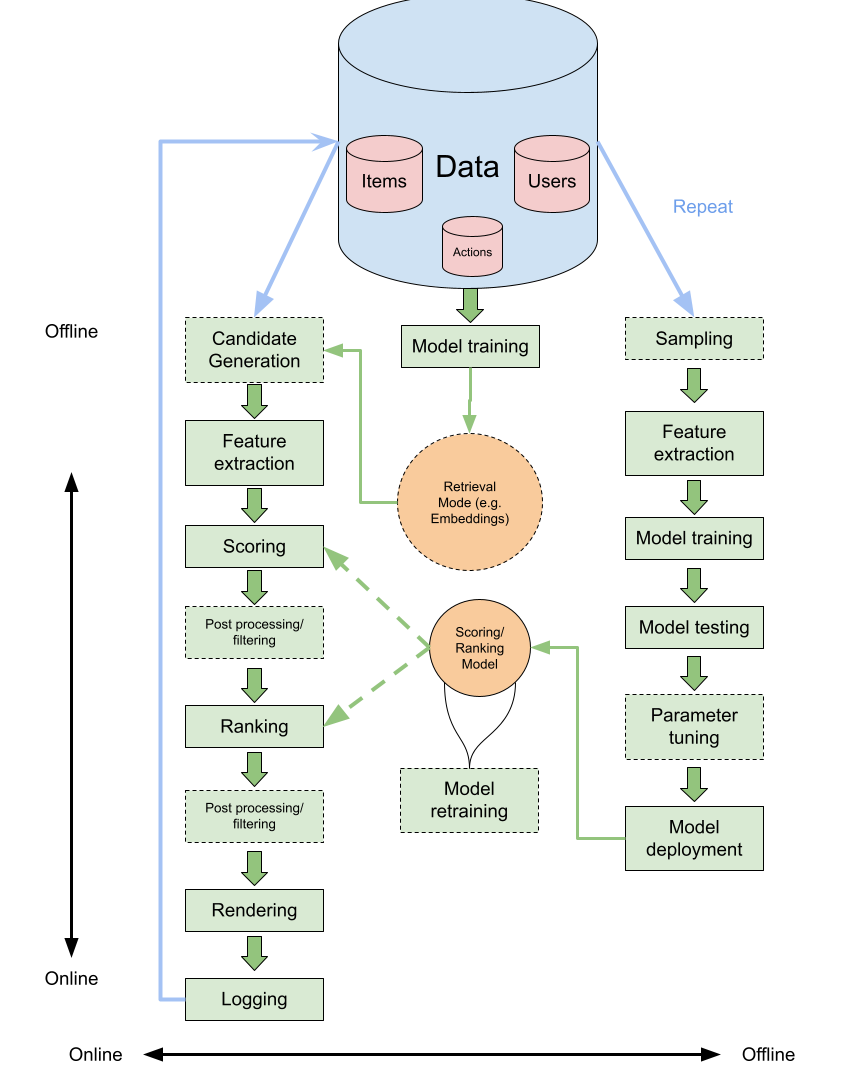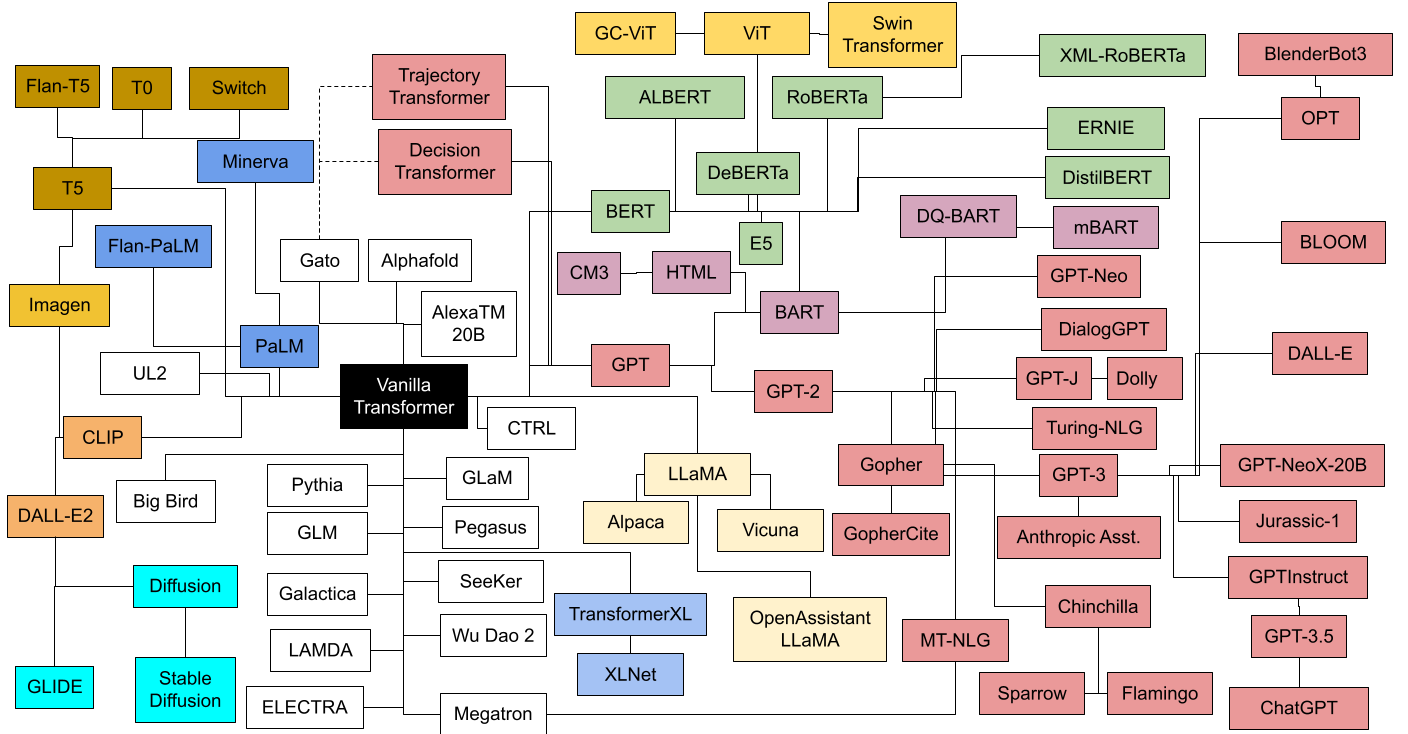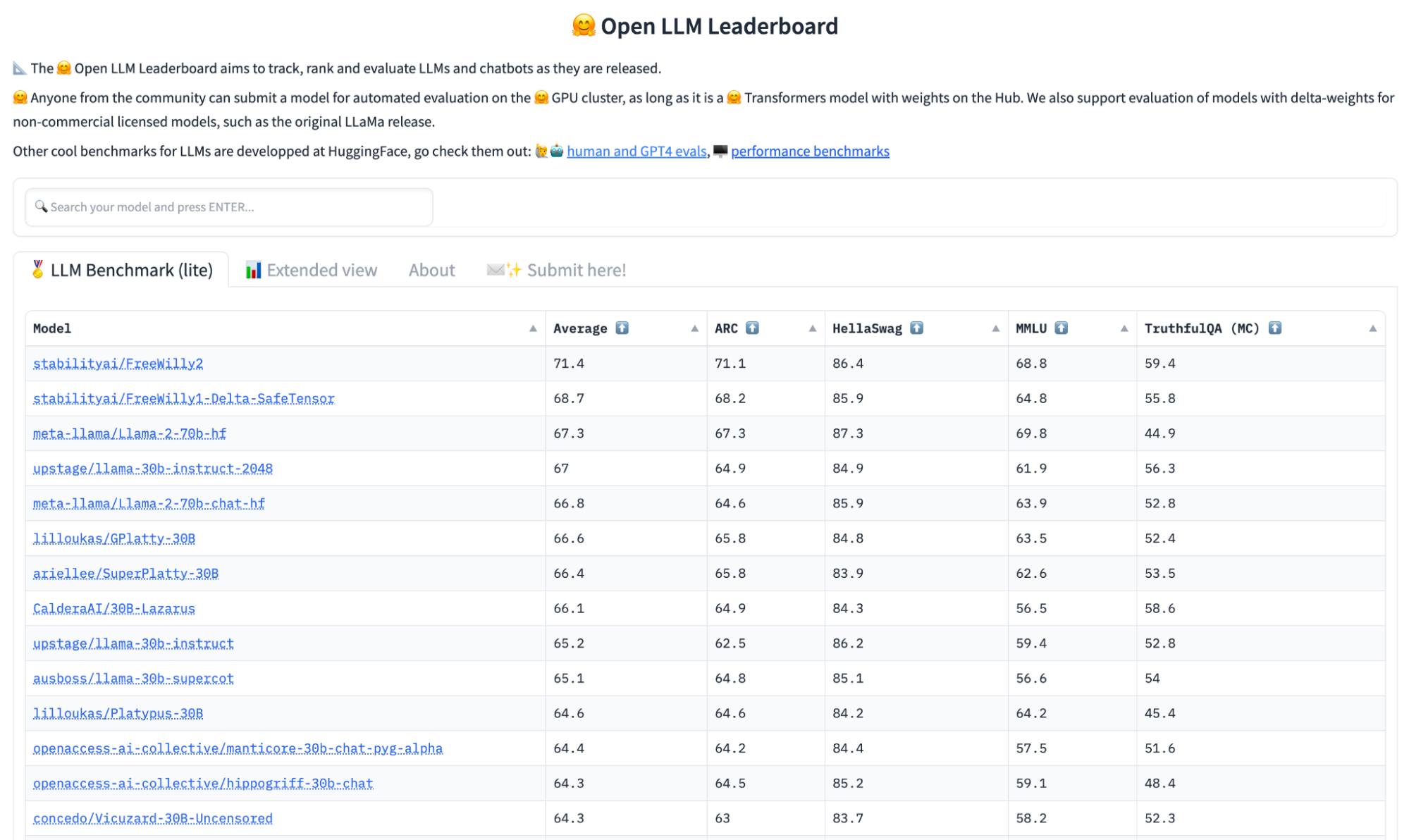
On open source LLMs, take two: The three laws of GenAI model evolution
In this post I summarize the main advances in the area of LLM models, and particularly open source LLMs (including Falcon, LlaMa2, and Free Willy). I describe different leaderboards and what their ...