A year of reasoning, agents, and compressed innovation cycles
If 2024 was the year of the chatbot, 2025 has been the year AI started to think—or at least, the year we started debating what “thinking” really means. It has been a year of profound shifts: from simple instruction following to complex reasoning, from “vibes” to verifiable actions, and from general-purpose models to specialized agents. It has also been a year of significant change for me personally, as I moved on from Google to explore new challenges.
This recap is based on a set of monthly reports I wrote throughout 2025, originally as a way to keep track of the fast‑moving AI landscape for myself and for my team at Google. Over time, those notes became a disciplined way to separate signal from noise and to understand how individual launches and papers fit into a broader trajectory.
2025 turned out to be a year of both acceleration and recalibration. Breakthroughs in reasoning models, agents, multimodality, and efficiency continued at a remarkable pace, while questions around economics, safety, and real‑world impact became harder to ignore. Stepping back each month made it easier to see which themes truly mattered.
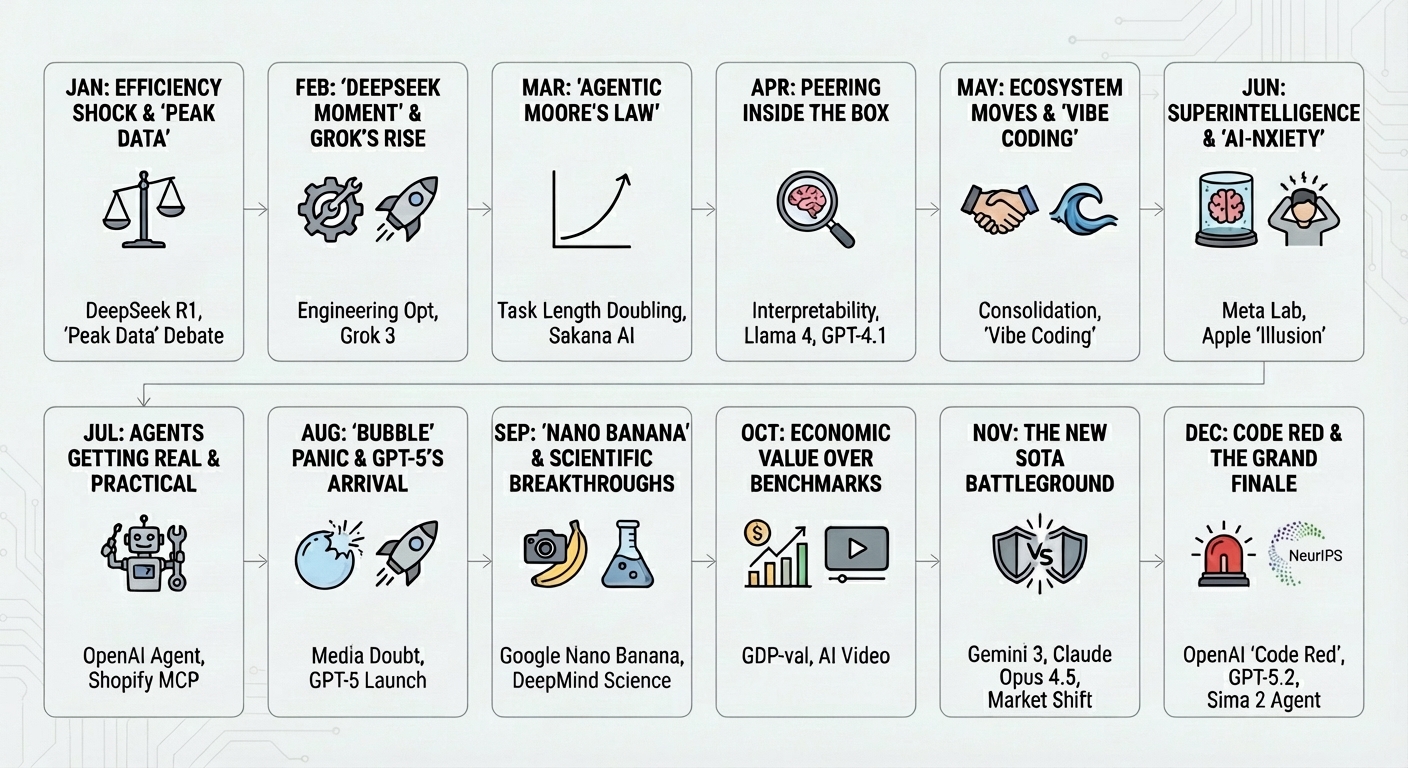
What follows is a month‑by‑month synthesis of those notes originally gathered for my internal newsletter at Google, curated and lightly expanded for this recap. The goal is not to be exhaustive, but to capture how the year actually unfolded. However, let me know if you are missing something important. I am also including direct links to monnths in case you have a favorite one!
- January: The Efficiency Shock and the “Peak Data” Debate
- February: The “DeepSeek Moment” and Grok’s Rise
- March: “Agentic Moore’s Law”
- April: Peering Inside the Box
- May: Ecosystem Moves and “Vibe Coding”
- June: Superintelligence and “AI-nxiety”
- July: Agents Getting Real and Practical
- August: The “Bubble” Panic and GPT-5’s Arrival
- September: “Nano Banana” and Scientific Breakthroughs
- October: Economic Value over Benchmarks
- November: The New SOTA Battleground
- December: Code Red and the Grand Finale
- What I Got Wrong in 2025
- Bonus: A Deeper Dive
- Conclusion
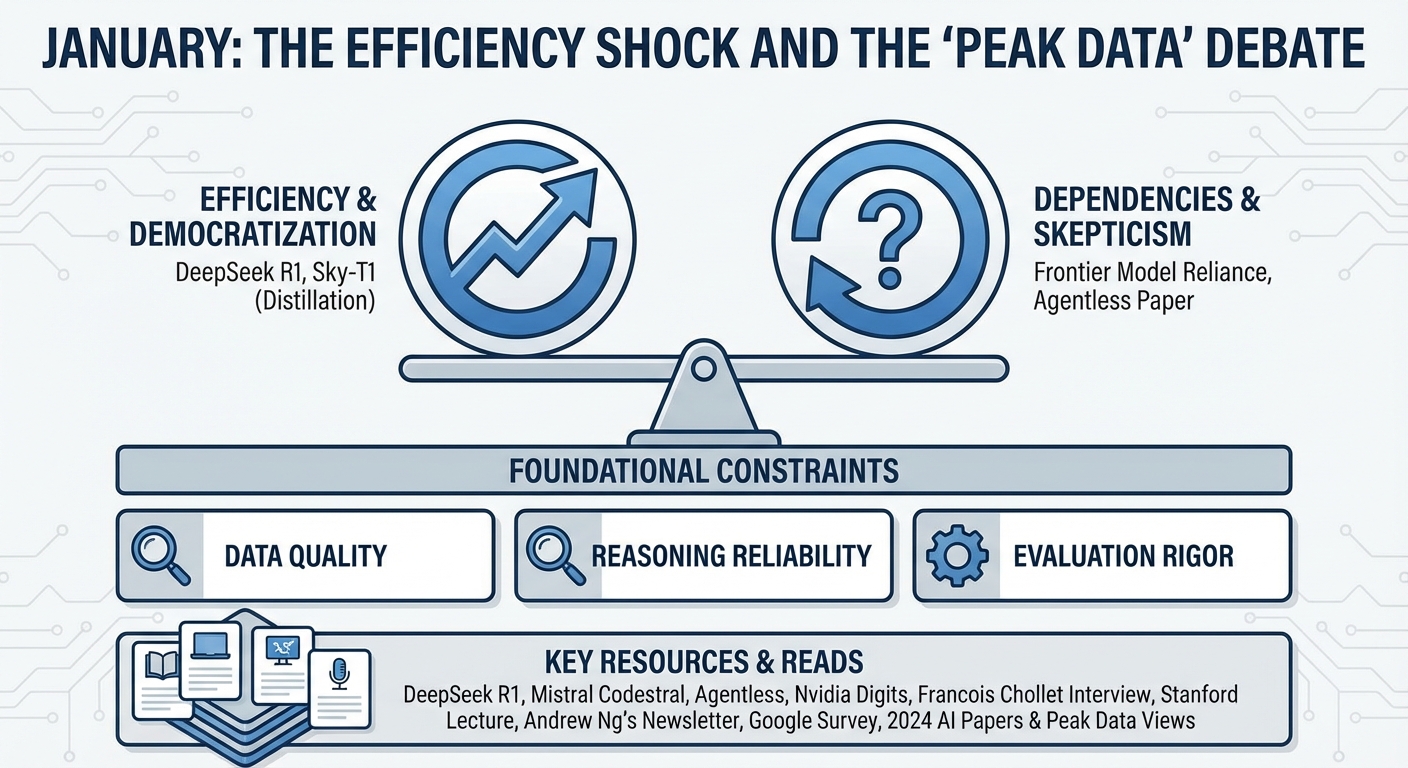
January: The Efficiency Shock and the “Peak Data” Debate
The year began with a wake-up call on efficiency. DeepSeek R1 made headlines not just for its performance, but for its remarkably low training cost, sparking a massive debate on whether we were entering a new era of “Post-Training” efficiency. While some celebrated this as a democratization moment, it’s important to read the fine print: techniques like distillation and fine-tuning are powerful, but they often rely on the existence of larger, more expensive frontier models. At the same time, we saw healthy skepticism emerge regarding agents, with papers arguing that for simple tasks, we might be over-engineering solutions.
- DeepSeek R1 reasoning model - The paper that started the year’s obsession with reasoning efficiency.
- Sky-T1 - Claiming 01-like performance on a mere $450 budget (distillation is key here!).
- Mistral Codestral - Mistral continuing to push the open-weight coding frontier.
- Agentless - A provocative paper arguing that for simple software engineering tasks, you might not actually need complex agents.
- Agents in Production Talks - A good collection of talks on agents in production (yes, these exist!).
- Nvidia Digits - Launching an AI desktop.
- Francois Chollet Interview - A must-watch discussion on AGI and how to measure it.
- Stanford Lecture on LLMs - Covering the often overlooked basics: tokenization, data, and evals.
- Andrew Ng’s Newsletter - Arguing that AI PMs are the future of software development teams.
- Google Survey on State of AI - An interesting multi-country pulse check.
- I compiled my favorite 2024 AI papers and shared my view on “Peak Data” and “Scaling Laws”.
January set the stage for a year where data quality, reasoning reliability, and evaluation rigor would repeatedly resurface as central constraints rather than secondary concerns.
February: The “DeepSeek Moment” and Grok’s Rise
February was dominated by the aftermath of DeepSeek and the surprise arrival of Grok 3. We spent weeks dissecting the DeepSeek papers, realizing that while it wasn’t necessarily a fundamental research breakthrough, it was a fantastic engineering feat that cleverly optimized known techniques. Meanwhile, Grok 3’s arrival—developed by a small team in just 18 months—shook up the leaderboards. We also began to realize that benchmarks are becoming increasingly “gameable” via test-time compute, making “Price vs. Performance” the new metric that matters.
- Grok 3 - Developed in just 18 months by a small team, hitting Rank 1 on Chatbot Arena.
- Imarena Price Plot - The new “Arena-Price Plot” became the most important chart for a few weeks.
- Semianalysis: DeepSeek Debates - A deep dive into Chinese leadership on cost and true training margins.
- Stratechery’s DeepSeek FAQ - Ben Thompson’s breakdown of the situation.
- [OpenAI Operator] (https://openai.com/index/introducing-operator/) and Deep Research- OpenAI’s response, pushing into agentic research.
- Perplexity Deep Research - Perplexity quickly following suit with their own implementation.
- Humanity’s Last Exam - A benchmark attempting to evaluate true reasoning capabilities.
- Mistral “Fastest Chatbot” - Powered by Cerebras hardware.
- AI Assisted CUDA Kernels - Nvidia and Sakana.ai showing how AI can write low-level code.
- Google Gemini 2.0 Flash - Competitive pressure driving efficiency.

February made clear that efficiency breakthroughs amplify—not reduce—the need for transparency, reproducibility, and robust evaluation.
March: “Agentic Moore’s Law”
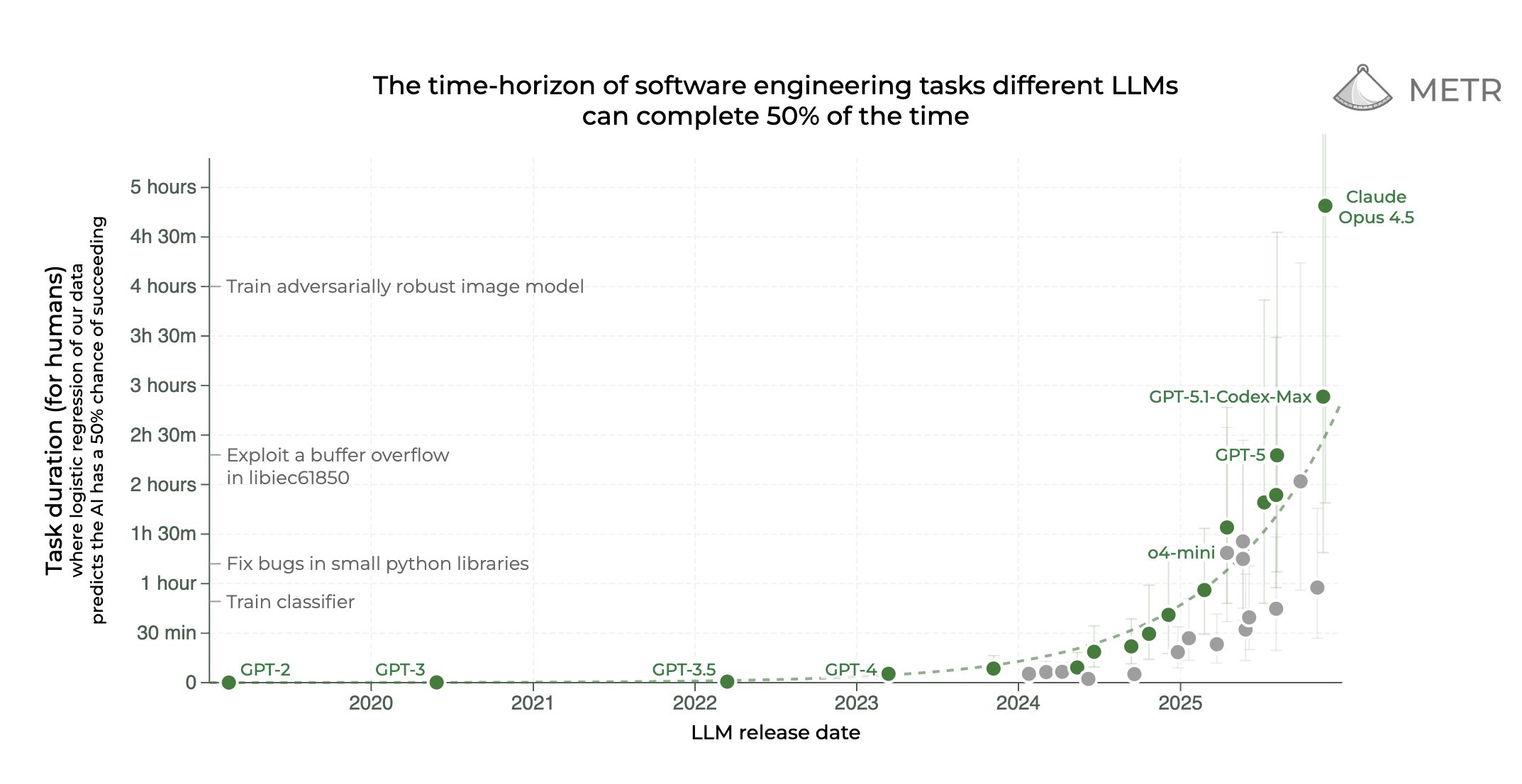
By March, the conversation shifted heavily toward Agents. We started seeing real data suggesting an “Agentic Moore’s Law,” where the length of tasks agents can solve autonomously is doubling roughly every 7 months. This was also the month Andrej Karpathy dropped his “Deep Dive,” reminding us that despite the hype, LLMs still struggle with basic token-level tasks (like counting ‘r’s in “strawberry”) and that prompting is still very much an art form.
- Karpathy’s Deep Dive into LLMs - Explaining why LLMs can’t count “r’s” in “strawberry” and why RLHF isn’t “true RL”.
- The “Agentic Moore’s Law” - Interesting data showing the length of tasks agents can solve is doubling every 7 months.
- Sakana AI Scientist - Generating the first peer-reviewed scientific publication entirely by AI.
- Manus: The General AI Agent - Another contender in the general agent space.
- MultiAgentBench - Evaluating how agents collaborate and compete.
- YC AI Codebases - A quarter of YC startups now have codebases that are almost entirely AI-generated.
- Interview Coder - The viral tool (and cheating concern) for coding interviews.
- Model Context Protocol (MCP) - Why standardizing context matters for tools.
- Large Language Diffusion Models - Exploring diffusion for text generation.
- Perplexity Comet - A browser designed specifically for agentic search.
- Pushing AI into the physical world with Gemini Robotics
- Introducing Gemma 3, highly capable for single GPU/TPU
- Enhancements to Google Search with AI Overviews and a new AI Mode
March previewed a broader shift toward autonomy and structured reasoning that would accelerate throughout the year.
April: Peering Inside the Box
April was about peering inside the black box. Anthropic released fascinating research on tracing the internal “thoughts” of models, while Meta’s Llama 4 release highlighted a crucial finding: Reinforcement Learning is proving much more important than Supervised Fine-Tuning (SFT). In fact, the data suggested that too much SFT can actually hurt performance. This was also the month OpenAI released GPT-4.1, which felt like a minor iteration compared to the architectural shifts we were seeing elsewhere.
- Tracing the Thoughts of an LLM - Anthropic’s fascinating research on internal activations.
- Introducing Llama 4 - Meta moving to Mixture of Experts (MoEs) and huge base models (“Behemoth”).
- Llama 4 and the Benchmark Crisis - The Verge’s take on how Llama 4 broke our evaluation metrics.
- Shopify’s AI Mandate - Tobi Lütke’s internal memo mandating AI usage for employees.
- Stanford AI Index 2025 - The state of AI in 10 charts.
- OpenAI GPT-4.1 - A minor improvement that noticeably lacked comparisons to non-GPT models.
- Project AMIE Nature Paper on diagnostic accuracy and on assisting clinicians - Two publications on conversational medical AI.
- DolphinGemma - Using AI to decode dolphin communication (yes, really).
- Cloud Next 2025 and infrastructure announcements
April reinforced that evaluation quality and RL‑driven training were no longer optional—they were becoming core pillars of progress. At the same time, some serious questions came up about the validity of public benchmarks.
May: Ecosystem Moves and “Vibe Coding”
May felt like a consolidation month. OpenAI went on an acquisition spree (buying Jony Ive’s startup and Windsurf), signaling a push into hardware and broader ecosystems. Meanwhile, Mark Zuckerberg was on a podcast tour with a refreshing level of honesty, admitting that Llama is essentially a byproduct of Meta’s internal needs rather than a purely altruistic developer play. We also saw the rise of “Vibe Coding”—a development style prioritized by speed and flow over rigorous syntax—gaining legitimacy. Coding, multimodality, and enterprise applications increasingly shared the same underlying capabilities, even as models became more specialized at the surface.
- OpenAI buys Jony Ive’s hardware startup
- Zuckerberg on Llama - His podcast tour explaining Llama as a byproduct of internal needs.
- Anthropic Claude Opus 4 and Sonnet 4 - Continued pressure at the high end.
- Google I/O 2025 announcements https://blog.google/technology/ai/google-io-2025
- Microsoft Build 2025 - 50+ announcements for developers.
- Vibe Coding Podcast - The AI Daily Brief on the state of “vibecoding.”
- The Effect of ChatGPT on Students - A Nature article providing valuable data on AI in education.
- Brakes on Intelligence Explosion - Nathan Lambert offering a counterpoint to the “AGI by 2027” hype.
- Netflix AI Search - Generative AI hitting mainstream consumer UI.
- AlphaEvolve - AI designing algorithms to save compute costs.
June: Superintelligence and “AI-nxiety”
In June, the race for “Superintelligence” became explicit, with Meta forming a dedicated lab and aggressively poaching talent (reportedly paying 7-to-9 figures). But alongside this race, we started seeing the human cost: “AI-nxiety.” Developers and users alike expressed exhaustion at the relentless pace of updates. We also saw Apple release their “Illusion of Thinking” paper, a controversial splash that argued current reasoning models might be shallower than we assume—a debate that is still ongoing.
- Meta’s Superintelligence Lab - Poaching Scale AI’s CEO to lead the charge.
- OpenAI hits $10B ARR - The business of AI is booming.
- UAE Free ChatGPT - A nation-state strategy to accelerate adoption.
- LangChain Keynote - Harrison Chase on the state of agents.
- Apple’s “Illusion of Thinking”- A controversial paper arguing models might not be reasoning as deeply as we think.
- Apple WWDC - Apple continuing to play catch-up in the generative race.
- Scaling Reinforcement Learning - Semianalysis on why RL is the next frontier.
- What’s Next for RL - Nathan Lambert’s take.
- AI-nxiety - “AI is Awesome but It’s Fucking Exhausting.”
- Infrastructure constraints and energy considerations for AI data centers
June underscored a recurring theme: progress is increasingly gated by infrastructure, incentives, and workflows—not by model quality alone.
July: Agents Getting Real and Practical
July saw agents moving from cool demos to practical, integrated products. OpenAI merged their Operator and Deep Research teams, signaling that agents are the new search. We also saw smart implementation tactics from companies like Shopify, who are building innovative agents that access internal data via the Model Context Protocol (MCP). The economic argument also solidified this month: we began to see compelling evidence that LLM inference costs are dropping fast enough to potentially become cheaper than traditional search.
- Zuckerberg’s Superintelligence Memo - Now public.
- OpenAI ChatGPT Agent - Merging Operator and Deep Research into one system.
- Gemini Deep think formally achieves gold-medal at the International Mathematical Olympiad
- Moonshot Kimi K2 - Reaching #1 on open model spots.
- xAI releases Grok4
- Shopify’s AI Tactics - Building innovative agents accessing internal data via MCPs.
- The AI-Native Employee - Papers on how AI is changing the nature of work and teamwork.
- Karpathy’s YC Lecture - “Software in the Era of AI.”
- Prompt Attacks on Papers - Researchers injecting prompts to prevent negative AI reviews.
- Inference vs. Search Costs - Arguing that LLM inference is becoming cheaper than traditional search.
- CLI version of Gemini gets over 50k stars in github in a few weeks
July made clear that productivity gains are earned through structural change, not incremental tooling.
August: The “Bubble” Panic and GPT-5’s Arrival
August was a rollercoaster of sentiment. We had a wave of “AI Bubble” articles from major publications asking if we had peaked, citing failed pilots and high costs. Then, almost on cue, GPT-5 launched. While the rollout was rocky and required adjustments, the sheer user numbers (700M weekly users) and valuation ($500B) largely silenced the “dead end” narrative. It was a reminder that while the hype might fluctuate, the utility is scaling.

- OpenAI had a momentous month, launching GPT-5, though the rollout was rocky and required adjustments based on user feedback.
- The AI Bubble Articles- Fortune , The Atlantic , and New Yorker all asking if we’ve peaked.
- Anthropic Opus 4.1 - Focus on safety and interpretability (persona vectors).
- Meta Personal Superintelligence - Leaning into their vision.
- Microsoft Github Spark - Their take on “vibecoding.”
- Figma Make - Vibecoding comes to design.
- Semianalysis: Scaling Memory - The roadmap of HBM.
- Synthetic Data for Pretraining - Lessons from scaling synthetic data (arXiv).
- Data efficiency breakthroughs via high-fidelity labeling
- Genie-style world models and simulation advances
- Coverage of AI energy usage and efficiency trade-offs
- Waymo 100M Miles - Autonomous driving quietly hitting massive milestones.
The month surfaced doubts around real progress in AI with the backdrop of many launches that seemed to prove those with doubts were probably wrong.
September: “Nano Banana” and Scientific Breakthroughs
September was a huge month for Google, led by the viral success of the Nano Banana image editing model. But beyond the consumer hype, we saw incredible scientific work from DeepMind on fluid dynamics and a continued push for safer, more accessible AI.
- Google Nano Banana - The viral image editing model that pushed the Gemini app to #1.
- The discussion continues on AI’s impact on the job market: a Harvard study suggests AI is “choking” entry-level hiring, while a Stanford study makes similar claims.
- Meta is pushing further into hardware with its AI-powered smart glasses
- DeepMind Fluid Dynamics - Using Physics-Informed Neural Networks to discover new mathematical edge cases in fluid motion.
- Coding Wins - Google and OpenAI showing dominance at university coding competitions.
- Gemini in Chrome - Embedding models directly into the browser for billions of users.
- Frontier Safety Framework - Google DeepMind’s third iteration of their safety framework.
- Agent Payments Protocol (AP2) - An open protocol for secure agent-led payments.
- Time’s 2025 AI 100 - The annual list of influential AI leaders.
- Anthropic announced a massive new funding round ($13B at a $183B valuation) as they scale to over 300k enterprise customers.
- xAI released Grok 4 Fast making a claim to be at the frontier of cost-efficient intelligence.
- Replit Agent 3 and multi-hour autonomy
September signaled a new baseline: autonomy and reliability were becoming table stakes.
October: Economic Value over Benchmarks
The focus in October was heavily on the new possibilities of AI video creation and proving the economic value of AI. The GDP-val paper was a standout, proposing that we measure frontier models not by academic exams, but by their ability to perform “economically valuable” tasks.
- OpenAI Dev Day- Announcing the Atlas browser, Instant Checkout, and Sora 2, their new video model and a dedicated app for short-form, AI-generated videos.
- Anthropic Sonnet 4.5 - And “Imagine” for real-time UI generation.
- Meta Vibes - Feed for short-form AI video.
- GDP-val - Finding frontier models rival humans on economically valuable tasks.
- GenAI and Firm Productivity - Measuring real-world impact in retail.
- US economic dependence on data-center buildout
- DeepSeek Sparse Attention - New research from the efficiency kings.
- Karpathy’s Nanochat - “The best ChatGPT that $100 can buy.”
- Tinker - Thinking Machines’ tool for model fine-tuning.
- Gemini Enterprise - Major steps for cloud customers.
- Sparse attention and efficiency work from DeepSeek
- A Bloomberg feature detailed the web of circular deals among AI companies
- Interesting discussions on the Dwarkesh podcast. While RL pioneer Richard Sutton argued that LLMs are a dead end, Andrej Karpathy presented a contrasting perspective
Progress increasingly began to be evaluated economically, not just technically.
November: The New SOTA Battleground
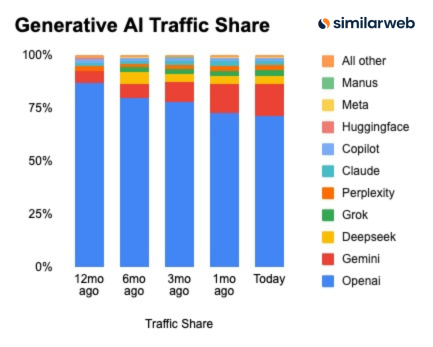
November brought the year’s biggest shakeup: the launch of Gemini 3. Google’s latest model, accompanied by the new “Deep Think” reasoning mode and the “Google Antigravity” agentic platform, immediately topped the charts. Just days later, Anthropic countered with Claude Opus 4.5, marketed as the ultimate coding model with massive improvements in agentic workflows. The market share data reflects this shift—ChatGPT is no longer the default for everyone.
- Google Gemini 3 - A huge shakeup with enhanced reasoning and agentic capabilities.
- Nano Banana Pro - Building on the viral success of the original, this version pushed image editing even further.
- Claude Opus 4.5 - A SOTA coding model that reportedly scores 74.5% on SWE-bench Verified.
- ChatGPT losing market share - Data from Similarweb showing a clear trend towards Gemini.
- Similarweb Analysis - Further confirmation of the changing landscape. Pie
- SIMA 2 embodied agent research
November felt like a visible inflection point in both capability and market momentum. SOTA leadership, once measured in years, was now clearly measured in weeks.
December: Code Red and the Grand Finale
The year ended with high drama. Feeling the heat from Gemini 3 and Opus 4.5, OpenAI declared a “Code Red,” reminiscent of Google’s own similar move back in 2022. This urgency birthed GPT-5.2, a rapid iteration designed to reclaim the throne, alongside new features like ChatGPT Images. Meanwhile, at NeurIPS 2025 in San Diego, the buzz was all about embodied agents, with DeepMind unveiling Sima 2, a generalist agent for 3D worlds that feels like a real step towards general purpose robotics.
- OpenAI Code Red - Sam Altman rallying the troops as competition heats up.
- GPT 5.2 Launch - OpenAI’s rapid response to the shifting benchmarks.
- ChatGPT Images - Bringing native image capabilities to the forefront.
- Gemini 3 Flash - A speed-optimized beast that still manages ~78% on SWE-bench Verified.
- Shipping Sora for Android - A fascinating look at how OpenAI used Codex to build their own app in just 28 days.
- DeepMind Sima 2 - A generalist embodied agent for 3D worlds, unveiled just in time for the conference season.
- NeurIPS 2025 conference and proceedings. Also, interestingly, several VCs are now giving good summaries of the conference. * * Here is the one by Amplify Partners and here the one by Radical Ventures.
The year closed with a clear signal: fast iteration now coexists with renewed investment in long‑horizon research.
What I Got Wrong in 2025
Looking back at my own predictions (and anxieties) from the start of the year, a few things stand out: The Bubble That Wasn’t: In August, amidst the “Peak AI” narrative, I worried we were heading for a winter. I was wrong. The utility of these models in coding and enterprise workflows has created a floor for value that is much higher than I anticipated. Agents are Harder than We Thought: I expected autonomous agents to be “solved” by mid-year. Instead, we found that reliability at scale is an immense challenge. The “Agentic Moore’s Law” is real, but the slope is shallower than I hoped. The Persistence of Open Weights: I feared the gap between closed and open models would widen to a chasm. Instead, thanks to DeepSeek, Mistral, and Meta, the open ecosystem is arguably healthier than ever, keeping the giants honest on price.
Bonus: A Deeper Dive
Before closing out the year, I sat down for an in-depth, 2-hour conversation with Jon Hernandez on his “Inteligencia Artificial” podcast. We covered everything from my transition out of Google and the internal dynamics of big labs, to why I believe “AGI” is a distracting term and why we should focus on specialized agents instead. If you want the unfiltered, “director’s cut” version of my take on 2025 and beyond, this is it.
Conclusion
As I close out my recap of 2025, I am struck by how much the narrative has changed. We are no longer just awed by the fluency of LLMs; we are now demanding fidelity, reasoning, and autonomy. The battles of November and December proved that no lead is safe, and “SOTA” is a title you hold for weeks, not months.
Leaving Google this year has given me a fresh perspective on this ecosystem. The rate of change is dizzying, but it is also exhilarating. As we head into 2026, I am more convinced than ever that we are just scratching the surface of what is possible when we combine powerful reasoning foundation models with verifiable reasoning and agentic workflows. I look forward to exploring all of this in the incredible space of Travel from my new position as Chief AI and Data Officer at Expedia Group.
Here’s to a 2026 full of verified rewards and fewer hallucinations. Happy New Year!