2024 has been an intense year for AI. While some argue that we haven’t made much progress, I beg to differ. It is true that many of the research advances from 2023 have still not made it to mainstream applications. But, that doesn’t mean that research is not making progress all around!
Every month I send my team at Google a few paper recommendations. For this end-of-year blog post, I went through all my monthly emails, picked my favorite articles, and I grouped them into categories. In each category I kept them ordered by publication date, so you may get a sense of progress in each of them.
Of course, this is a highly curated and probably biased list. I hope you enjoy it, and please let me know what was your favorite paper that I missed!
 Imagen3. Prompt= “Futuristic cityscape under construction in 2024, representing rapid progress in AI research, many buildings under construction, robots, drones, holographic blueprints, but also trees and nature and happy people and children, each building a different research area, detailed, cinematic lighting, concept art, warm colors”
Imagen3. Prompt= “Futuristic cityscape under construction in 2024, representing rapid progress in AI research, many buildings under construction, robots, drones, holographic blueprints, but also trees and nature and happy people and children, each building a different research area, detailed, cinematic lighting, concept art, warm colors”
- LLMs, surveys and new models
- New techniques
- RAG and beyond
- Domain-specific applications of LLMs
- AI Security and alignment
- Agents
- LLM Evaluation
- Beyond LLMs
LLMs, surveys and new models
- Large Language Models: A Survey - This comprehensive survey paper, which I had the privilege of co-authoring, provides a broad overview of the rapidly evolving landscape of Large Language Models (LLMs). It covers everything from model architectures and training techniques to applications and ethical considerations. I was particularly interested in contributing to the section on prompt engineering, agents, and post-attention LLMs. It’s been incredibly gratifying to see this paper cited nearly 500 times in less than a year, highlighting the immense interest in this field. A must-read for anyone looking to get up to speed on LLMs.
- The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits - This paper introduces BitNet, a groundbreaking approach to training LLMs that drastically reduces the precision of model parameters to just 1.58 bits, effectively making each parameter ternary (-1, 0, or +1). While reducing precision this drastically might seem counterintuitive, the authors demonstrate that BitNet models achieve comparable performance to full-precision models while delivering significant improvements in latency, memory usage, throughput, and energy consumption. This could be a game-changer for deploying LLMs on resource-constrained devices and making them more environmentally sustainable. This work challenges the conventional wisdom that high precision is always necessary for LLM performance.
- Jamba: A Hybrid Transformer-Mamba Language Model - Jamba represents an exciting new direction in LLM architecture, combining the strengths of Transformers with the efficiency of Structured State Space Models (SSMs), specifically the Mamba architecture. This hybrid approach allows Jamba to handle longer contexts more effectively than traditional Transformers, while also being more computationally efficient. As one of the first open-source models to successfully integrate these two architectures, Jamba is a significant step towards building more powerful and scalable LLMs.
- PaliGemma: A versatile 3B VLM for transfer - PaliGemma, a new open-source vision-language model from Google DeepMind, stands out for its compact size (3 billion parameters) and its focus on transfer learning. Unlike many larger models that are trained from scratch for each new task, PaliGemma is specifically designed to be fine-tuned efficiently for a wide range of downstream applications. This makes it a particularly valuable tool for researchers and developers with limited resources, and it underscores the growing importance of transfer learning in the field of vision-language AI.
- Gemma 2: Improving Open Language Models at a Practical Size - The Gemma 2 report offers a treasure trove of insights into the training process of state-of-the-art LLMs. The authors delve into the details of their architectural choices, including variations on attention mechanisms and the use of knowledge distillation, all while prioritizing a model size that is practical for real-world use. This report is highly recommended for anyone interested in the nitty-gritty of LLM development and the trade-offs involved in optimizing for performance, efficiency, and accessibility.
- The Llama 3 Herd of Models - While the Llama 3 models from Meta don’t introduce radical architectural changes, they demonstrate the continued power of scaling up existing approaches. The key takeaway here is the sheer impact of using more data and larger models, combined with meticulous engineering. Llama 3 models achieve impressive results across a range of benchmarks, reaffirming that bigger (and with better data) often is better, at least for now. Still, it does make one wonder when diminishing returns will set in.
- Imagen3 - Imagen 3, Google’s latest text-to-image model, pushes the boundaries of image generation quality and control. It outperforms all other models, including DALL-E 3 and Midjourney v6, on most benchmarks, demonstrating a remarkable ability to translate complex textual prompts into highly detailed and coherent images. While Midjourney v6 still holds a slight edge in subjective visual appeal, Imagen 3’s superior performance on benchmarks requiring precise prompt adherence highlights its strength in controllability. This model represents a significant leap forward in text-to-image generation, bringing us closer to AI that can truly understand and visualize our creative visions.
- GPT-4o System Card - The GPT-4o System Card provides a crucial glimpse into the extensive safety work that went into OpenAI’s latest flagship model. It outlines the rigorous evaluations, including external red teaming and frontier risk assessments, that were conducted before its release. This document is a must-read for anyone interested in the ethical considerations surrounding advanced AI and the growing importance of proactive safety measures in the development of powerful language models.
- Llama 3.2: Revolutionizing edge AI and vision with open, customizable models - Meta’s release of Llama 3.2 models (both LLMs and VLMs) emphasizes the increasing demand for powerful yet efficient AI that can run on edge devices. These smaller models achieve state-of-the-art performance for their size, making them suitable for deployment on smartphones, wearables, and other resource-constrained hardware. This is a significant step towards democratizing access to advanced AI and enabling a new wave of on-device applications.
- Movie Gen: A Cast of Media Foundation Models - Meta’s MovieGen showcases the impressive capabilities of foundation models in the realm of multimedia generation. This collection of models achieves state-of-the-art results on a wide range of tasks, including text-to-video, video-to-audio, and text-to-audio generation. This work highlights the growing power of AI to create and manipulate different forms of media, opening up exciting possibilities for creative expression and content generation.
- Deepseek v3 technical report - The DeepSeek-V3 technical report is a testament to the fact that you don’t need a massive budget to build a state-of-the-art LLM. This model has been making waves in the AI community due to its impressive performance, achieved with a surprisingly small training budget. This report provides valuable insights into how to efficiently train high-performing LLMs, making it a valuable resource for researchers and developers working with limited resources.
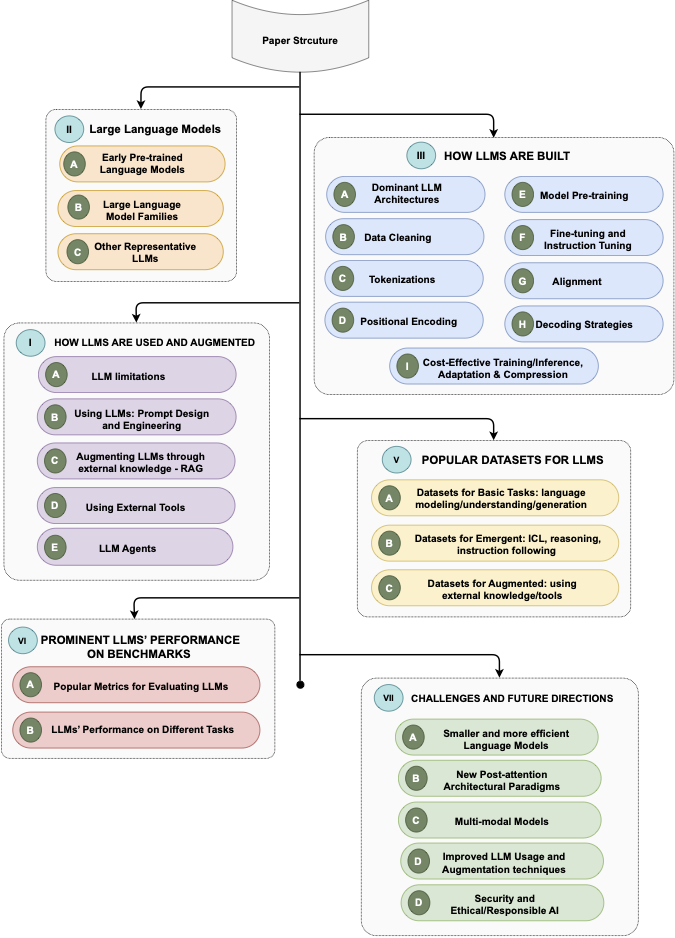 From our “Large Language Models: A Survey” paper
From our “Large Language Models: A Survey” paper
New techniques
- GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection - GaLore introduces a novel training strategy that tackles the memory bottleneck of training large language models. By using gradient low-rank projection, it enables full-parameter learning while being significantly more memory-efficient than popular methods like LoRA. This could open up new possibilities for training larger and more complex models on existing hardware, pushing the boundaries of what’s possible in LLM research..
- Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention - Infini-attention offers a clever solution to the context length limitations of Transformers. This new attention mechanism allows for efficient processing of arbitrarily long contexts, even on LLMs with a relatively small number of parameters. By improving both context length and inference efficiency, Infini-attention could enable LLMs to process and understand much larger documents and conversations, unlocking new applications in areas like document summarization, question answering, and dialogue systems.
- The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale - This paper from HuggingFace tackles the crucial issue of data quality in LLM training. The authors present a new dataset called FineWeb, which is carefully curated from web data using a rigorous filtering and cleaning process. This work highlights the importance of high-quality data for achieving optimal LLM performance and provides a valuable resource for researchers working on improving the quality of web-scale datasets.
- Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet - This fascinating work from Anthropic delves into the inner workings of LLMs, demonstrating a method for extracting interpretable features from the Claude 3 Sonnet model. Not only can they identify these features, but they also show how they can be manipulated to control the model’s output. This research provides valuable insights into the interpretability of LLMs and opens up exciting possibilities for steering their behavior in a more fine-grained way. I find this area to be one of the most important in the path to safe AGI.
- Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality - This paper makes the surprising and insightful claim that Transformers, the dominant architecture in modern LLMs, are actually a specific type of Structured State Space Model (SSM). This connection opens up new avenues for understanding and potentially improving both Transformers and SSMs. By revealing this underlying duality, the authors provide a unifying framework that could lead to the development of more generalized and efficient models for sequence processing.
- Scalable MatMul-free Language Modeling - This paper challenges the fundamental reliance on matrix multiplications (MatMul) in Transformer architectures. The authors demonstrate that it’s possible to build language models without any MatMul operations, potentially leading to significant improvements in computational efficiency. This is a radical departure from conventional approaches and could pave the way for new hardware architectures optimized for language modeling.
- LoRA+: Efficient Low Rank Adaptation of Large Models - LoRA+ builds upon the popular LoRA (Low-Rank Adaptation) technique, further enhancing its efficiency by dynamically adjusting the learning rate for different parameters during fine-tuning. This relatively simple yet effective modification can lead to faster convergence and improved performance when adapting large models to new tasks, making it a valuable tool for practitioners working with LLMs.
- Self-Play Preference Optimization for Language Model Alignment - This paper introduces a novel alternative to Reinforcement Learning from Human Feedback (RLHF) for aligning language models with human preferences. Instead of relying on external human feedback, it uses a self-play mechanism where the model competes against itself to improve its performance. This approach offers a potentially more scalable and efficient way to fine-tune LLMs for specific tasks or domains, and it raises interesting questions about the nature of learning and optimization in AI.
- Training Language Models to Self-Correct via Reinforcement Learning - This work from DeepMind explores the use of reinforcement learning to train language models to self-correct their mistakes. By incorporating a self-correction mechanism during training, the model learns to identify and rectify errors, leading to improved performance and robustness. The authors show that this approach can act as a form of regularization, preventing overfitting and improving generalization to unseen data.
- STAR: Synthesis of Tailored Architectures - The STAR paper introduces a novel approach to automatically designing neural network architectures using a gradient-free evolutionary algorithm. Instead of relying on manual design or gradient-based optimization, STAR explores a vast search space of architectures, evolving them over time to find optimal solutions. This work has the potential to automate the process of neural architecture search, leading to the discovery of new and potentially more efficient architectures for various tasks.
- What Matters in Transformers? Not All Attention is Needed - This paper investigates the inner workings of the Transformer architecture, questioning the necessity of every single attention head. Their findings suggest that current Transformer architectures contain redundancies, and that similar performance can be achieved with fewer attention mechanisms. This research could lead to more efficient Transformer designs and a deeper understanding of what makes them so effective.
- Cut Your Losses in Large-Vocabulary Language Models - This paper from Apple demonstrates a clever optimization technique for large-vocabulary language models. By implementing a custom kernel for matrix multiplication and log-sum-exp operations, they are able to significantly reduce computational cost and improve efficiency. The authors use the Gemma model as an example, showcasing the practical benefits of their approach. This is another great example of how low-level optimizations can have a big impact on the performance of large models.
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters - This paper challenges the conventional wisdom that bigger models are always better. The authors, from DeepMind, argue that scaling up computation at test time can be a more effective strategy than simply increasing the number of model parameters. While this idea has been recently popularized by speculation around OpenAI’s “O1” model, this paper provides the original research underpinning this concept. This highlights the importance of considering not just model size but also computational efficiency during inference, and it opens up new avenues for optimizing LLM performance.
- Large Concept Models: Language Modeling in a Sentence Representation Space - Meta’s research on Large Concept Models (LCMs) explores a fascinating new direction for language modeling. Instead of predicting individual tokens, LCMs operate in a sentence representation space, predicting hierarchical concepts. This approach could potentially lead to more abstract and human-like understanding of language. While still early, this work suggests that there’s more to language modeling than just token prediction, and it opens up exciting new avenues for research into higher-level reasoning and understanding.
- Pushing the frontiers of audio generation - “Having worked on audio synthesis myself many years ago, I’ve been consistently amazed by the rapid progress in AI-driven audio generation. This blog post from DeepMind provides an overview of the research that has led to these breakthroughs, covering areas like neural audio codecs and diffusion models. This is a great read for anyone interested in the intersection of AI and audio, and it showcases the incredible potential of AI to generate realistic and creative soundscapes.
RAG and beyond
- In Defense of RAG in the Era of Long-Context Language Models - This paper makes a compelling case for the continued relevance of Retrieval-Augmented Generation (RAG) even as LLMs with increasingly long context windows become available. The authors argue that RAG is not simply a workaround for limited context length but offers distinct advantages in many scenarios, such as when dealing with rapidly evolving information or when needing to provide sources for generated text. This is a valuable read for anyone working with LLMs, as it challenges the assumption that longer context windows will necessarily replace retrieval-based methods.
- Introducing Contextual Retrieval - “Anthropic’s work on contextual retrieval introduces a refined approach to RAG that takes into account the broader context of a query when retrieving relevant information. They propose two main techniques—contextual embeddings and contextual BM25—to improve the accuracy and relevance of retrieved passages. This research highlights the ongoing efforts to make RAG systems more sophisticated and context-aware, potentially leading to more accurate and nuanced responses from LLMs.
- From Local to Global: A Graph RAG Approach to Query-Focused Summarization - This paper from Microsoft explores a novel approach to query-focused summarization using a graph-based RAG system. By representing information as a graph, the model can better capture the relationships between different pieces of information and generate more coherent and comprehensive summaries. This work demonstrates the potential of graph-based methods for enhancing RAG systems and tackling complex information retrieval tasks.
Domain-specific applications of LLMs
- Capabilities of Gemini Models in Medicine - This paper showcases the impressive capabilities of Google’s multimodal Gemini models in the medical domain. The results are quite striking: Gemini models outperform medical experts on a wide range of tasks, including medical image interpretation, diagnosis, and report generation. This research underscores the transformative potential of AI in healthcare, although it also raises important questions about the role of human expertise in the future of medicine.
- NExT: Teaching Large Language Models to Reason about Code Execution - The NExT paper presents a method for teaching LLMs to reason about the execution of code, a crucial step towards building more reliable and trustworthy AI for software development. The authors demonstrate that LLMs can learn to accurately predict the output of code snippets, even for complex programs. This research has significant implications for automating code analysis, debugging, and even code generation, potentially leading to substantial gains in programmer productivity.
- Automated Social Science: Language Models as Scientist and Subjects - This paper explores the intriguing possibility of using LLMs to automate social science research. By combining structural causal models with the reasoning capabilities of LLMs, the authors propose a framework for conducting automated experiments and generating hypotheses. While still in its early stages, this research opens up exciting new avenues for using AI to accelerate scientific discovery in the social sciences, potentially leading to a deeper understanding of human behavior and social phenomena.
- 3DS: Decomposed Difficulty Data Selection’s Case Study on LLM Medical Domain Adaptation - This paper challenges the common practice of domain adaptation and fine-tuning LLMs for specific medical tasks. The authors argue that frontier models, such as GPT-4, are already good enough for many medical applications, even without specialized training. They introduce a method called 3DS that selects training data based on decomposed difficulty levels. This research questions some of the prevailing assumptions about the need for extensive domain adaptation in every case and suggests that the capabilities of general-purpose LLMs might be underestimated in specialized domains like medicine.
AI Security and alignment
- ArtPrompt: ASCII Art-based Jailbreak Attacks against Aligned LLMs - This paper reveals a surprising vulnerability in aligned LLMs: they can be jailbroken using carefully crafted ASCII art prompts. This might seem whimsical at first, but it highlights the fragility of current alignment techniques and the creative ways in which adversaries might try to circumvent them. This research underscores the need for more robust and comprehensive methods for aligning LLMs with human values and preventing them from being misused.
- AGI Safety and Alignment at Google DeepMind: A Summary of Recent Work - This paper provides a valuable overview of Google DeepMind’s extensive research on AGI safety and alignment. It covers a wide range of topics, including scalable oversight, robustness, and system safety. This is a key read for anyone interested in the long-term safety of AI and the challenges of ensuring that increasingly powerful AI systems remain aligned with human goals.
- Foundational Challenges in Assuring Alignment and Safety of Large Language Models - This multi-institution paper delves into the fundamental challenges of ensuring the alignment and safety of LLMs. It provides a framework for understanding the different types of alignment failures and outlines key research directions for addressing them. This paper is a valuable contribution to the growing field of AI safety and highlights the need for collaborative efforts to tackle these complex issues.
- Quantifying Misalignment Between Agents: Towards a Sociotechnical Understanding of Alignment - This paper extends the discussion of alignment beyond individual models to the realm of multi-agent systems. The authors argue that misalignment between agents can be just as important, if not more so, than misalignment between a model and human values. They propose a framework for quantifying misalignment in multi-agent settings. This work highlights the need to consider the broader social and technical context in which AI systems operate and to develop methods for ensuring that agents can effectively cooperate and coordinate with each other.
Agents
- CoSearchAgent: A Lightweight Collaborative Search Agent with Large Language Models - The CoSearchAgent paper introduces a lightweight, collaborative search agent that leverages the power of multiple specialized LLMs. By dividing the search task among different agents, each with its own expertise, the system can achieve more comprehensive and accurate results. This research demonstrates the potential of multi-agent systems for tackling complex information retrieval tasks and highlights the benefits of a collaborative approach.
- Mixture-of-Agents Enhances Large Language Model Capabilities - This work from Together.ai provides further evidence for the power of multi-agent systems. They show that combining agents built using smaller, open-source models can outperform even the most advanced, monolithic LLMs on certain tasks. This research suggests that the future of AI might lie not in ever-larger single models but in well-designed systems of interacting, specialized agents.
- Husky: A Unified, Open-Source Language Agent for Multi-Step Reasoning - The Husky paper, with authors from Meta and other institutions, introduces a new open-source language agent designed for multi-step reasoning. This general-purpose agent can tackle a wide range of tasks that require planning and problem-solving. The release of Husky as an open-source tool is a significant contribution to the field, providing researchers and developers with a powerful platform for building and experimenting with language agents.
- LangChain State of AI Agents - This report from the LangChain team provides a comprehensive overview of the rapidly evolving field of AI agents. It covers the different types of agents, the key challenges in building them, and the most promising applications. This is an excellent resource for anyone looking to get up to speed on the current state of agent research and development.
LLM Evaluation
- Who Validates the Validators? Aligning LLM-Assisted Evaluation of LLM Outputs with Human Preferences - This paper tackles the crucial issue of evaluating LLMs, particularly when using other LLMs as evaluators. The authors introduce EvalGen, an interface that allows humans to grade LLMs on their ability to evaluate other LLMs, thus aligning the evaluation process with human preferences. This research highlights the importance of meta-evaluation in the development of LLMs and provides a practical tool for improving the reliability of LLM-assisted evaluations.
- Vibe-Eval: A hard evaluation suite for measuring progress of multimodal language models - The Vibe-Eval benchmark, introduced by researchers at Reka AI, offers a new and challenging way to evaluate multimodal LLMs. It focuses on tasks that require a deep understanding of both visual and textual information. The introduction of this benchmark will push the development of more robust and capable multimodal models, helping us measure true progress in this important area.
Beyond LLMs
- Accurate structure prediction of biomolecular interactions with AlphaFold 3 - AlphaFold 3 represents a major breakthrough in the field of structural biology. This latest iteration of DeepMind’s protein folding model can now predict the structure and interactions of a wide range of biomolecules, including proteins, DNA, and RNA, with unprecedented accuracy. The release of the AlphaFold Server, a free tool for researchers, promises to dramatically accelerate research in drug discovery, materials science, and our fundamental understanding of biological processes. This is a landmark achievement that has the potential to revolutionize many areas of science.
- New Computer Evaluation Metrics for a Changing World - This paper argues for the need to rethink traditional computer performance metrics in light of the changing landscape of computing. The authors, my colleagues at Google, propose new metrics that take into account factors like energy efficiency, sustainability, and the specific needs of modern workloads, such as AI and machine learning. This is a timely and important contribution that will be relevant to anyone involved in designing, evaluating, or using computer systems.
- Hardware Trends Impacting Floating-Point Computations In Scientific Applications - This paper explores the complex interplay between hardware trends and the precision requirements of scientific computing. The authors analyze how different floating-point formats and hardware architectures affect the accuracy and performance of scientific applications. This research provides valuable insights for developers of scientific software, helping them navigate the trade-offs between precision, performance, and efficiency in the context of evolving hardware.
 Imagen3. Prompt = “2024, AI research depicted as a challenging mountain range, climbers making progress on each peak, representing breakthroughs and ongoing efforts, detailed, cinematic lighting, concept art”
Imagen3. Prompt = “2024, AI research depicted as a challenging mountain range, climbers making progress on each peak, representing breakthroughs and ongoing efforts, detailed, cinematic lighting, concept art”

Comments