(This blog post, as with most of my recent ones, is written with AI assistance and augmentation. In this case, “We” in the text refers to myself and my local OpenClaw agent, which has been my primary co-developer throughout this project.)
Most AI demos today suffer from a “low-ceiling” problem: they stop at “look, it can answer a question.” I wanted to push toward the actual horizon of this technology—an assistant that doesn’t just predict the next token, but personalizes recommendations, reasons with deep context, and executes real-world tasks.
That vision became Recommend Flow: a multi-agent architecture built on OpenClaw. The project hinged on one key architectural decision: instead of generating recommendations in a vacuum, the orchestrator first consults Xavibot v0.1 —my original assistant—as a “preference proxy.” Note that Xavibot is implemented using a completely different technology stack, leveraging Google’s Gemini models and a custom Retrieval-Augmented Generation (RAG) pipeline to ensure its “intuition” is grounded in my actual history.
The “We” and the Machine
A quick note on the terminology: when I say “we,” I am being quite literal. This system was deployed and refined in collaboration with a local OpenClaw agent running on a dedicated Linux machine in my home office. I communicate with the system primarily through WhatsApp, often using voice messages for convenience. The local agent handles the transcription, intent extraction, and orchestration.
One of the most pragmatic features of this setup is how it handles the “last mile” of execution. By utilizing browser navigation on my local machine, the bot doesn’t need to know my passwords or handle sensitive credentials. It simply leverages the active logins already present in my local browser sessions. While this requires the machine to be secure, it keeps the identity risk isolated and avoids the headache of managing a separate “vault” of API keys for every third-party service.
Furthermore, we’ve leaned into the philosophy of “Memory as Documentation.” All agent memories and complex workflows are stored locally as simple .md files. This approach offers several advantages:
- Maintenance & Transparency: I can literally cat a memory file to see exactly what the agent “knows” or “remembers” about my tastes. If it learns a wrong preference, I fix the text file.
- Portability: The entire intelligence of the system—the workflows, the personality priors, and the task histories—lives in a folder that can be moved across machines or version-controlled via Git.
- Security Guardrails: Storing workflows in plain text allows for human-readable audit trails. I can verify the steps the agent intends to take before it ever touches a browser.
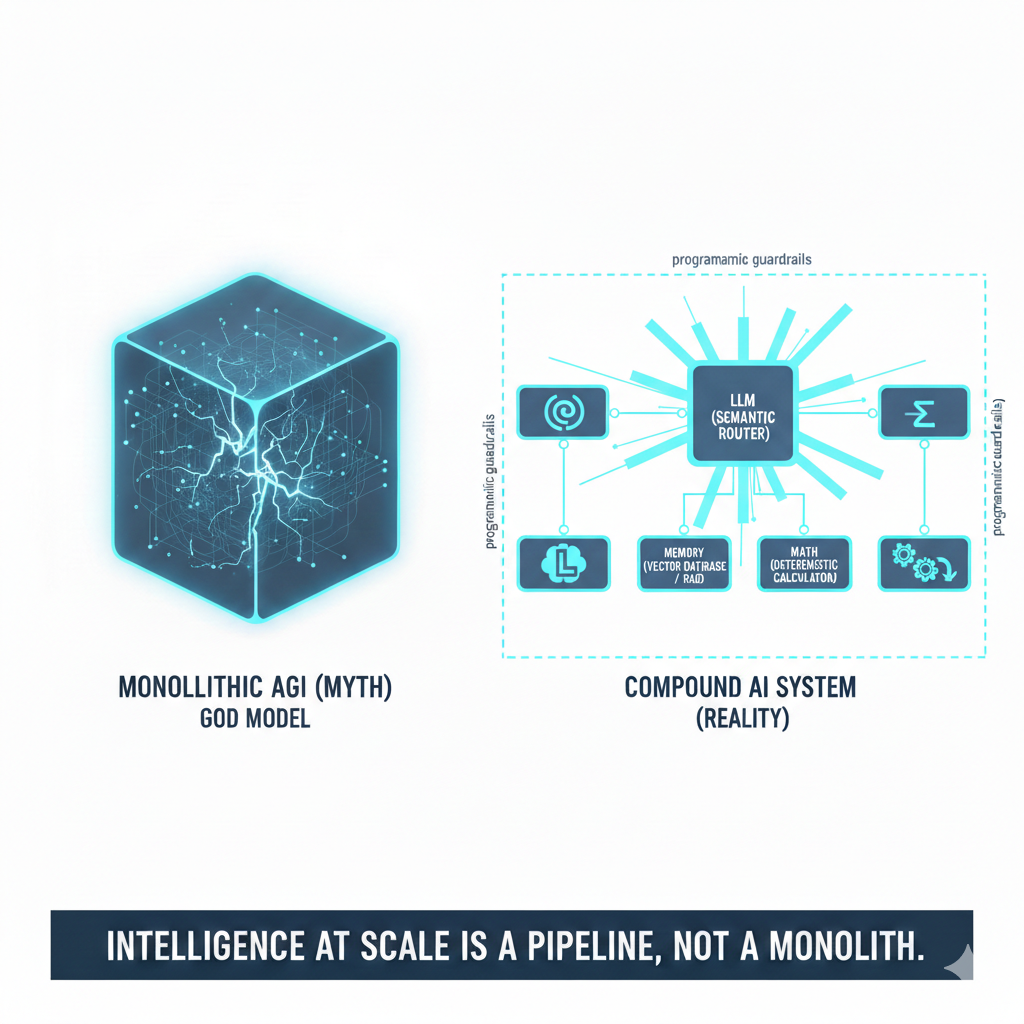
The Big Idea: Separate Roles, Compose Capabilities
In a previous post, I argued that modern LLMs are evolving into “reasoning engines.” In Recommend Flow, we intentionally split those reasoning responsibilities:
- The Orchestrator (OpenClaw session): This agent serves as the central brain and primary interface. While it often communicates via WhatsApp, it also supports a local browser-based UX for more interactive sessions. Crucially, the orchestrator manages the Recommend Flow—the set of hard rules and constraints that define the recommendation process. However, it isn’t a rigid state machine; it has the autonomy to improvise and handle edge cases outside of the predefined flow when necessary.
- The Preference Proxy (Xavibot v0.1): This is not just another LLM endpoint. It runs RAG (Retrieval-Augmented Generation) over a broad corpus of my own material—blog posts, personal guides, and private documents. It acts as the “taste model,” carrying my content memory and style priors.
- The Execution Layer (Browser Automation): Completes the workflow (e.g., booking a table or adding an item to a cart) using the local browser.
This separation matters. A single model trying to handle high-level preference reasoning and low-level DOM manipulation is often brittle. A role-specialized setup is easier to debug, tune, and—most importantly—trust.
How Recommend Flow Works (End-to-End)
The interaction follows a disciplined Recommend → Decide → Do loop:
- Voice/Text Intent: I send a WhatsApp message: “Hey, find me a place for dinner tonight that I haven’t been to but fits my usual vibe.”
- Preference Interrogation: The Orchestrator acknowledges the request and immediately queries Xavibot v0.1: “Based on Xavier’s past writing on food and his local guide, what are his core dining preferences?”
- Constraint Refinement: The system brings those signals back and asks for missing details (e.g., location or specific timing) one at a time.
- The Decision Set: It returns a compact “Top 1 + Backup 1” recommendation with explicit tradeoffs based on my retrieved preferences.
- Action Execution: Once I give the “Go”, the local Linux agent wakes up the browser, navigates to the reservation site, and executes the task using my existing login.
Watch the Recommend Hotel Reservation Demo below or you can open it here
*In this demo I have a chat with my Openclaw instance (called Xavibot) using a local browser for easier recording (as mentioned I usually interface through Whatsapp). Note that the browsing on the Chrome browser on the left is completely autonomous. In fact, at some point Openclaw decided to Google for “best restaurants in Palo Alto on OpenTable” that was a surprise.”
Why Xavibot v0.1 is the Perfect Backbone
As I’ve explored in my Data-Informed Gut Decision-Making framework, good decisions require a mix of data and intuition. Xavibot v0.1 brings three properties that are hard to fake with prompting alone:
- Grounded Memory: RAG over a vast collection of my writings, personal guides, and miscellaneous documents give- s persistent, high-signal context. It has even surprised me by surfacing details I’d forgotten I documented—like my preference for avoiding spicy foods, an observation it pulled from deep within my records.
- Taste Continuity: It reflects my historical writing and constraints, acting as a “digital twin” of my preferences.
What We Learned (and What Broke)
- Multi-agent beats monolith: Role separation reduced prompt complexity and made behavior consistent.
- Personalization is a loop, not a profile: Static “user profile” fields are useful, but conversational updates (context, mood, live constraints) matter just as much.
- Action design needs strict guardrails: People forgive imperfect suggestions; they don’t forgive wrong actions. We learned to make recommendations “cheap” to generate, but transactions require explicit, high-confidence confirmation.
- Isolation is a security feature: Running the browser automation locally on my own machine, rather than in a cloud-hosted container, provided a natural security boundary that felt much safer for a personal project.
Conclusion: The Future of Agentic Execution
The most interesting part of this project isn’t that an AI can recommend a restaurant; it’s the architectural pattern. This combination of preference-grounded reasoning, specialized agents, and tool-based execution is a blueprint that generalizes to travel planning, shopping, gifting, or even professional hiring workflows.
If the previous wave of AI was about assistants that could answer, this is the wave of assistants that can decide with you and then execute for you.


Comments