(This blog post, as most of my recent ones, is written with AI assistance and augmentation. First time using nano banana for the infographics!)
In a previous post, we delved into “Beyond Token Prediction: the post-Pretraining journey of modern LLMs” to explore the multifaceted post-pretraining life of modern LLMs. A key takeaway from that discussion was that modern LLMs have evolved far beyond simple next-token prediction, a point that becomes even more critical as we venture into the realm of reasoning models. We touched upon how techniques like Reinforcement Learning from Human Feedback (RLHF) have been pivotal in aligning these models with human preferences. But the world of AI moves at a dizzying pace, and the conversation is already shifting. While RLHF has been a cornerstone, the new rave is all about Reinforcement Learning with Verifiable Rewards (RLVR), a term introduced in this recent paper. This isn’t just an incremental update; it’s a paradigm shift that could be the key to unlocking true reasoning in our models.
From Human Preference to Verifiable Truth
So, what exactly is RLVR, and how does it differ from the RLHF we’ve grown accustomed to? RLHF, in essence, is about teaching a model to be more “human-like.” We show it two responses, a human indicates which one is “better,” and the model learns to produce outputs that are more likely to be preferred. It’s a powerful technique for improving style, tone, and safety. However, it’s also inherently subjective. What one person prefers, another might not. And more importantly, a preferred answer isn’t always the correct answer, especially when it comes to complex reasoning tasks.
This is where RLVR comes in. As the name suggests, RLVR is a flavor of reinforcement learning where the reward is based on a verifiable, objective metric. Instead of asking “which answer do you like more?”, we ask “is this answer demonstrably correct?”. The reward is no longer a matter of opinion but of fact. For example, if we’re training a model to solve a math problem, the reward can be based on whether the final answer is correct. If we’re teaching it to code, the reward can be tied to whether the code compiles and passes a set of unit tests.

The folks at Fireworks.ai have been doing some fantastic work in this area, and their blog post on the topic is a must-read. They highlight that RLVR is particularly well-suited for tasks where the “goodness” of an output can be programmatically determined. This shift from subjective human feedback to objective, verifiable rewards is a subtle but profound one. It’s the difference between a model that’s a good conversationalist and one that’s a reliable problem-solver.
Diving Deeper: Reward Functions, Learned Models, and Policy Optimization
To appreciate the mechanics of RLVR, it helps to distinguish between a programmatic reward function and a learned reward model. RLVR’s power stems from its use of a programmatic reward function—essentially, a piece of code that deterministically scores an output. For example: if unit_tests_pass(): return 1.0 else: return 0.0. This is transparent, objective, and verifiable. In contrast, traditional RLHF uses a learned reward model, which is a separate neural network trained on human preference data to predict what score a human would give. This model is an approximation of human values and can have its own biases or be gamed.
Once you have a method for scoring responses, you need an algorithm to update the LLM’s policy (the “actor”). The workhorse here is PPO (Proximal Policy Optimization). It’s important to clarify a potential point of confusion: while RLVR avoids the learned reward model of RLHF, PPO itself, as an actor-critic method, often learns an auxiliary Value Network (the “critic”). This network doesn’t judge preference; instead, it estimates the expected future reward from a given state (i.e., the sequence of tokens generated so far). By comparing the actual reward to the critic’s prediction, PPO calculates the “Advantage”—a more stable signal for how good an action was. PPO uses this Advantage to update the actor in small, stable steps, maximizing the reward while ensuring the updated model doesn’t stray too far from its original state. This is a crucial safeguard against a common pitfall in RL known as reward hacking, where the model exploits an unforeseen loophole in the reward function to get a high score without achieving the intended goal. As detailed in a great SemiAnalysis article, this is a major challenge. The constraints in PPO help prevent this kind of undesirable optimization, making it a foundational technique for both RLHF and RLVR.
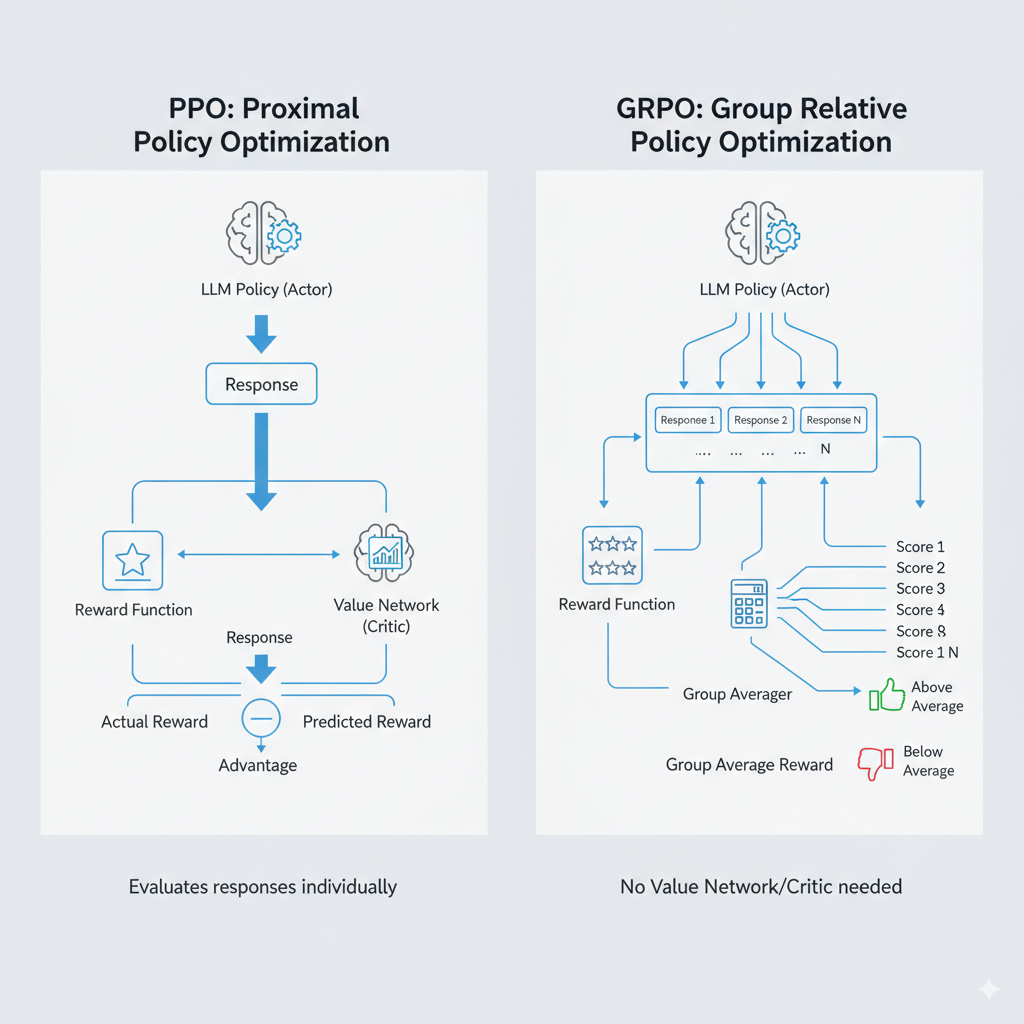
The field is moving fast, and simpler, more stable alternatives to PPO are emerging. A prominent example, brought to light by the team behind the Deepseek R1 model (as detailed in this Hugging Face post), is GRPO (Group Relative Policy Optimization). Unlike PPO, which evaluates responses individually, GRPO operates on a group of candidate responses for a given prompt. A key difference and advantage is its simplicity, as GRPO does not need to learn an auxiliary value function. For each prompt, it samples multiple outputs, calculates the average reward for this group, and then updates the policy based on the relative performance of each sample. The objective is to encourage responses that score above the group average and discourage those that fall below. This approach of using a group’s average performance as a dynamic baseline provides a more stable and robust training signal, reducing the variance that can make PPO tricky to tune. It’s particularly effective for complex reasoning tasks where a clear “winner” is less important than consistently moving towards better-than-average solutions. For those interested in a hands-on implementation, the team at Lightning AI has a great post on building a reasoning LLM from scratch using GRPO.
The Key to Unlocking Reasoning
Our ultimate goal is to teach models to reason, not just to mimic patterns of text that have been positively reinforced by humans. When a model is rewarded not just for the final answer, but for the steps it takes to get there, it learns a process. This idea was formalized into a technique known as Process Supervision, where a reward is provided for each correct step in a model’s reasoning chain, leading to the development of Process-based Reward Models (PRMs).
As detailed by OpenAI in their work on improving mathematical reasoning, instead of only rewarding the final answer (outcome supervision), Process Supervision rewards the model for each correct intermediate step. You can find more technical details in the original research paper. This is where things get really exciting. Imagine a model that can show its work, and we can verify and reward each step of that work. This not only makes the model’s reasoning process more transparent but also allows us to pinpoint exactly where it goes wrong and provide targeted feedback. This is a much more powerful and scalable approach than simply telling the model “your answer is wrong” and hoping it figures out why.
However, it’s crucial to draw a distinction here. While PRM-based training looked like the primary path forward a year ago, many of the biggest recent wins have come from simpler forms of RLVR—often just binary, outcome-based checkers combined with massive sampling and efficient algorithms like GRPO (see Nathan’s comment in Interconnects.ai blog post, “What Comes Next with Reinforcement,” ). This doesn’t mean PRMs have disappeared; rather, their role has evolved. They are now shifting to two key areas: as a crucial verifier at inference time to check the model’s reasoning, and for targeted training where step-level fidelity and interpretability are paramount. So, while still highly relevant, PRMs are becoming a specialized tool within the broader and more versatile RLVR toolkit.
Beyond just improving reasoning on static problems, RL is also a foundational component for training autonomous agents that can interact with environments and learn from the consequences of their actions. The shift is so significant that, as detailed in a recent piece by SemiAnalysis, the growing importance of RL is fundamentally changing the structure of AI research labs. As this insightful video on the future of AI agents explains, this sets the stage for continuous learning, where models can adapt and improve over time without constant, large-scale retraining.
Test-Time Compute: Getting More from Models at Inference
A model trained with RLVR provides a strong reasoning foundation, but its performance can be significantly amplified at inference through a strategy known as test-time compute. This refers to the computational effort a model expends when actively working on a prompt to arrive at a final answer. Instead of generating a single, immediate response, we can have the model engage in a more deliberative, multi-path reasoning process.
At inference time, we can scale up this compute by using techniques like Self-Consistency (sampling multiple reasoning paths and taking a majority vote on the final answer) or Tree-of-Thoughts (actively exploring a tree of possible reasoning steps). This allows the model to explore a wider solution space and self-correct. The final, crucial step is to use a verifier—which can be a simple programmatic check, a unit test, or even a PRM acting as a reranker—to select the best and most reliable answer from the many candidates generated. This purely inference-time strategy leverages the strong base model from RLVR training to achieve state-of-the-art accuracy and robustness on complex tasks.
Karpathy’s Corner: The Bull Case and a Word of Caution
No discussion of the future of AI would be complete without mentioning Andrej Karpathy. His insights are always a valuable addition to the conversation. In a recent tweet, he laid out his bull case for Reinforcement Learning, and it’s easy to see why he’s optimistic. The ability to fine-tune models based on specific, measurable outcomes is a powerful tool, and RLVR is a prime example of this.
However, Karpathy is also a pragmatist. In another tweet, he raised a crucial question about the scalability of reward functions. He expressed some doubt that we can design reward functions that can scale all the way to AGI. And he has a point. While it’s relatively straightforward to design a verifiable rewards for a math problem or a coding challenge, what’s the verifiable rewards for writing a beautiful poem or a compelling story? How do we create a reward function for “common sense”?
This is the central challenge we face. As we push our models to tackle more complex and nuanced tasks, the line between verifiable and subjective rewards will inevitably blur. But that doesn’t mean we should abandon the pursuit. The progress we’re seeing with RLVR in domains like math, science, and coding is a testament to its potential. It might not be the silver bullet that gets us all the way to AGI, but it’s a massive step in the right direction. It’s a step towards models that don’t just talk the talk but can actually walk the walk of reason. And that, in itself, is a revolution.
References
- Amatriain, X. (2024). Beyond Token Prediction: the post-Pretraining journey of modern LLMs. https://amatria.in/blog/postpretraining
- Minae, S., et al. (2024). Large language models: A survey. https://arxiv.org/abs/2402.06196
- Li, Z., et al. (2024). Reinforcement Learning with Verifiable Rewards. https://arxiv.org/abs/2411.15124
- Fireworks.ai. Reinforcement Learning with Verifiable Reward. https://fireworks.ai/blog/reinforcement-learning-with-verifiable-reward
- SemiAnalysis. (2025). Scaling Reinforcement Learning: Environments, Reward Hacking, Agents, & Scaling Data. https://semianalysis.com/2025/06/08/scaling-reinforcement-learning-environments-reward-hacking-agents-scaling-data/
- DeepSeek-AI. (2025). DeepSeek-V2: A Strong, Economical, and Open-Source Mixture-of-Experts Language Model. https://arxiv.org/html/2501.12948
- Uhr, N. (2025). Implementing Deepseek’s GRPO from scratch. Hugging Face Blog. https://huggingface.co/blog/NormalUhr/grpo
- Lightning AI. Build a reasoning LLM from scratch using GRPO. https://lightning.ai/lightning-purchase-test/studios/build-a-reasoning-llm-from-scratch-using-grpo?section=featured
- OpenAI. (2023). Improving mathematical reasoning with process supervision. https://openai.com/index/improving-mathematical-reasoning-with-process-supervision/
- Lightman, H., et al. (2023). Let’s Verify Step by Step. https://arxiv.org/abs/2305.20050
- Lambert, N. (2025). What Comes Next with Reinforcement. Interconnects.ai. https://www.interconnects.ai/p/what-comes-next-with-reinforcement
- The Future of AI Agents. (Video). https://www.youtube.com/watch?v=JIsgyk0Paic
- Wang, X., et al. (2022). Self-Consistency Improves Chain of Thought Reasoning in Language Models. https://arxiv.org/abs/2203.11171v4
- Yao, S., et al. (2023). Tree of Thoughts: Deliberate Problem Solving with Large Language Models. https://arxiv.org/abs/2305.10601v1
- Karpathy, A. (2025). Twitter Post on RL Bull Case. https://x.com/karpathy/status/1944435412489171119
- Karpathy, A. (2025). Twitter Post on Reward Function Scalability. https://x.com/karpathy/status/1960803117689397543

Comments