The discussion of whether it is better to focus on building better algorithms or getting more data is by no means new. But, it is really catching on lately. This was one of the preferred discussion topics in this year’s Strata Conference, for instance. And, I do have the feeling that because of the Big Data “hype”, the common opinion is very much favoring those claiming that it is “all about the data”. The truth is that data by itself does not necessarily help in making our predictive models better. In the rest of this post I will try to debunk some of the myths surrounding the “more data beats algorithms” fallacy.
The Unreasonable Effectiveness of a Misquote
Probably one of the most famous quotes defending the power of data is that of Google’s Research Director Peter Norvig claiming that “We don’t have better algorithms. We just have more data.”. This quote is usually linked to the article on “The Unreasonable Effectiveness of Data”, co-authored by Norvig himself (you should probably be able to find the pdf on the web although the original is behind the IEEE paywall). The last nail on the coffin of models is when Norvig is misquoted as saying that “All models are wrong, and you don’t need them anyway” (read here for the author’s own clarifications on how he was misquoted).
 |
The effect that Norvig et. al were referring to in this article, had already been captured years before in the famous paper by Microsoft Researchers Banko and Brill [2001] “Scaling to Very Very Large Corpora for Natural Language Disambiguation“. In that paper, the authors included the plot below.
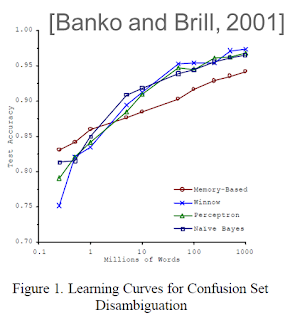 |
That figure shows that, for the given problem, very different algorithms perform virtually the same. however, adding more examples (words) to the training set monotonically increases the accuracy of the model.
So, case closed, you might think. Well… not so fast. The reality is that both Norvig’s assertions and Banko and Brill’s paper are right… in a context. But, they are now and again misquoted in contexts that are completely different than the original ones. But, in order to understand why, we need to get slightly technical. I don’t plan on giving a full machine learning tutorial in this post. If you don’t understand what I explain below, read Andrew Ng’s Practical Advice for Machine Learning. Or, better still, enroll in his Machine Learning course.
Variance or Bias?
The basic idea is that there are two possible (and almost opposite) reasons a model might not perform well.
In the first case, we might have a model that is too complicated for the amount of data we have. This situation, known as high variance, leads to model overfitting. We know that we are facing a high variance issue when the training error is much lower than the test error. High variance problems can be addressed by reducing the number of features, and… yes, by increasing the number of data points. So, what kind of models were Banko & Brill’s, and Norvig dealing with? Yes, you got it right: high variance. In both cases, the authors were working on language models in which roughly every word in the
vocabulary makes a feature. These are models with many features as
compared to the training examples. Therefore, they are likely to
overfit. And, yes, in this case adding more examples will help.
But, in the opposite case, we might have a model that is too simple to explain the data we have. In that case, known as high bias, adding more data will not help. See below a plot of a real production system at Netflix and its performance as we add more training examples.
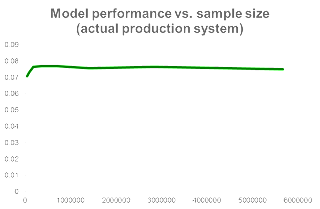 |
So, no, more data does not always help. As we have just seen there can be many cases in which adding more examples to our training set will not improve the model performance.
More features to the rescue
If you are with me so far, and you have done your homework in understanding high variance and high bias problems, you might be thinking that I have deliberately left something out of the discussion. Yes, high bias models will not benefit from more training examples, but they might very well benefit from more features. So, in the end, it is all about adding “more” data, right? Well, again, it depends.
Let’s take the Netflix Prize, for example. Pretty early on in the game, there was a blog post by serial entrepreneur and Stanford professor Anand Rajaraman commenting on the use of extra features to solve the problem. The post explains how a team of students got an improvement on the prediction accuracy by adding content features from IMDB.
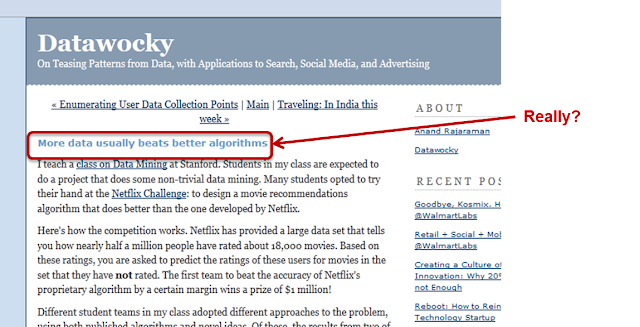 |
In retrospect, it is easy to criticize the post for making a gross over-generalization from a single data point. Even more, the follow-up post references SVD as one of the “complex” algorithms not worth trying because it limits the ability of scaling up to larger number of features. Clearly, Anand’s students did not win the Netflix Prize, and they probably now realize that SVD did have a major role in the winning entry.
As a matter of fact, many teams showed later that adding content features from IMDB or the like to an optimized algorithm had little to no improvement. Some of the members of the Gravity team, one of the top contenders for the Prize, published a detailed paper in which they showed how those content-based features would add no improvement to the highly optimized collaborative filtering matrix factorization approach. The paper was entitled “Recommending New Movies: Even a Few Ratings Are More Valuable Than Metadata“.
 |
To be fair, the title of the paper is also an over-generalization. Content-based features (or different features in general) might be able to improve accuracy in many cases. But, you get my point again: More data does not always help.
The End of the Scientific Method?
Of course, whenever there is a heated debate about a possible paradigm change, there are people like Malcolm Gladwell or Chris Anderson that make a living out of heating it even more (don’t get me wrong, I am a fan of both, and have read most of their books). In this case, Anderson picked on some of Norvig’s comments, and misquoted them in an article entitled: “The End of Theory: The Data Deluge Makes the Scientific Method Obsolete“.
 |
The article explains several examples of how the abundance of data helps people and companies take decision without even having to understand the meaning of the data itself. As Norvig himself points out in his rebuttal, Anderson has a few points right, but goes above and beyond to try to make them. And the result is a set of false statements, starting from the title: the data deluge does not make the scientific method obsolete. I would argue it is rather the other way around.
Data Without a Sound Approach = Noise
So, am I trying to make the point that the Big Data revolution is only hype? No way. Having more data, both in terms of more examples or more features, is a blessing. The availability of data enables more and better insights and applications. More data indeed enables better approaches. More than that, it requires better approaches.
 |
In summary, we should dismiss simplistic voices that proclaim the uselessness of theory or models, or the triumph of data over these. As much as data is needed, so are good models and theory that explains them. But, overall, what we need is good approaches that help us understand how to interpret data, models, and the limitations of both in order to produce the best possible output.
In other words, data is important. But, data without a sound approach becomes noise.
(Note: this post is based on a few slides included in my Strata talk a few months back. Those slides sparked an interesting debate, and follow up emails that prompted me to write these lines)

Comments