In this post I summarize the main advances in the area of LLM models, and particularly open source LLMs (including Falcon, LlaMa2, and Free Willy). I describe different leaderboards and what their current top positions mean. I enunciate the three laws of generative AI model evolution, and I ask GPT-4, Bard, and LlaMa 2 the implications of these laws.
Five months ago, I wrote about what open source LLMs meant for the future of AI. Here is what I had to say “back in the days”:
- The best LLMs are going to be much better in all the different dimensions you probably care about (including e.g. less hallucinations)
- The best open-source LLMs are going to be better than the best non-open source LLMs nowadays. As an example, Facebook AI made a big announcement for their LLaMA open source model a couple of weeks back . A few days later Google announced their Flan-UL2 20B model. The latter is much better. Not as good as GPT-3.5 yet, but getting close.
- While the best LLMs in (1) are going to continue to grow in size, there are going to be models that are much smaller than the current best models yet have better capabilities. Some of them might be open sourced in (2).
Of course, a lot of things happen in five AI months! Note that these words were written a few days even before GPT4 was publicly announced! I think they still hold very true so I will stick with my original prediction, but the purpose of this post is to update to the current day. So, let’s start with what has happened since then.
What’s new?
First, as already mentioned, GPT4. GPT4 blew everyone’s mind as I expected and knew because of the early access I had had for months.
GPT4 is still the SOTA and the one to beat that no other model has beat yet. It is, without any doubt much better than GPT-3.5,
so my (1) statement proved true (not a big surprise, particularly given that I had access to privileged information at that time).
Maybe the only model that has gotten close to challenging its supremacy is Claude 2 announced
by Anthropic only a few weeks back, but that model is also proprietary. So, “best models are proprietary” still holds.
There have been many advances in the open source arena, but two need to be underscored:
- Falcon LLM was announced initially in March, and its largest 40B version open sourced in May. Falcon quickly moved to the top of the leaderboards. Furthermore, it challenged many of the previous assumptions about where these open sourced models would come from. Falcon came from a research institute in the United Arab Emirates. So, not a tech company, and not even a US institution!
- LlaMa 2 (the new version of LlaMa) was announced by Meta last week. The largest version of the model has 70B parameters and is comparable to GPT4 in some dimensions.
- In just 2 days, Stability.ai presented a new fine-tuned version of LlaMa 2, Free Willy. This model beats all the other open source models, including LlaMa 2 on almost all benchmarks.
So, what do these really important milestones mean in relation to my original prediction? Well, we are getting open source models that are (far) better than the ones we had at the time of the writing. So, statement (2) was also correct.
Also, while models like GPT4 are huge and larger than anything that was public 5 months ago, we have models such as Falcon and LlaMa that are much smaller in size than GPT-3.5 (175B), yet much better. Again, statement (3) was also correct.
A few words on benchmarks and leaderboards
I am making some assertions above that might convey that evaluating models is easy and straightforward. However that is far from true. There are quite a few different benchmarks and leaderboards, and most don’t have overlapping models, so some conclusions need to be inferred and extrapolated from them. Let’s take a closer look at how the different benchmarks look right now.
Huggingface maintains an amazing and very up-to-date leaderboard, but it only has open source models. At the time of this writing it is dominated by Free Willy and Llama2.
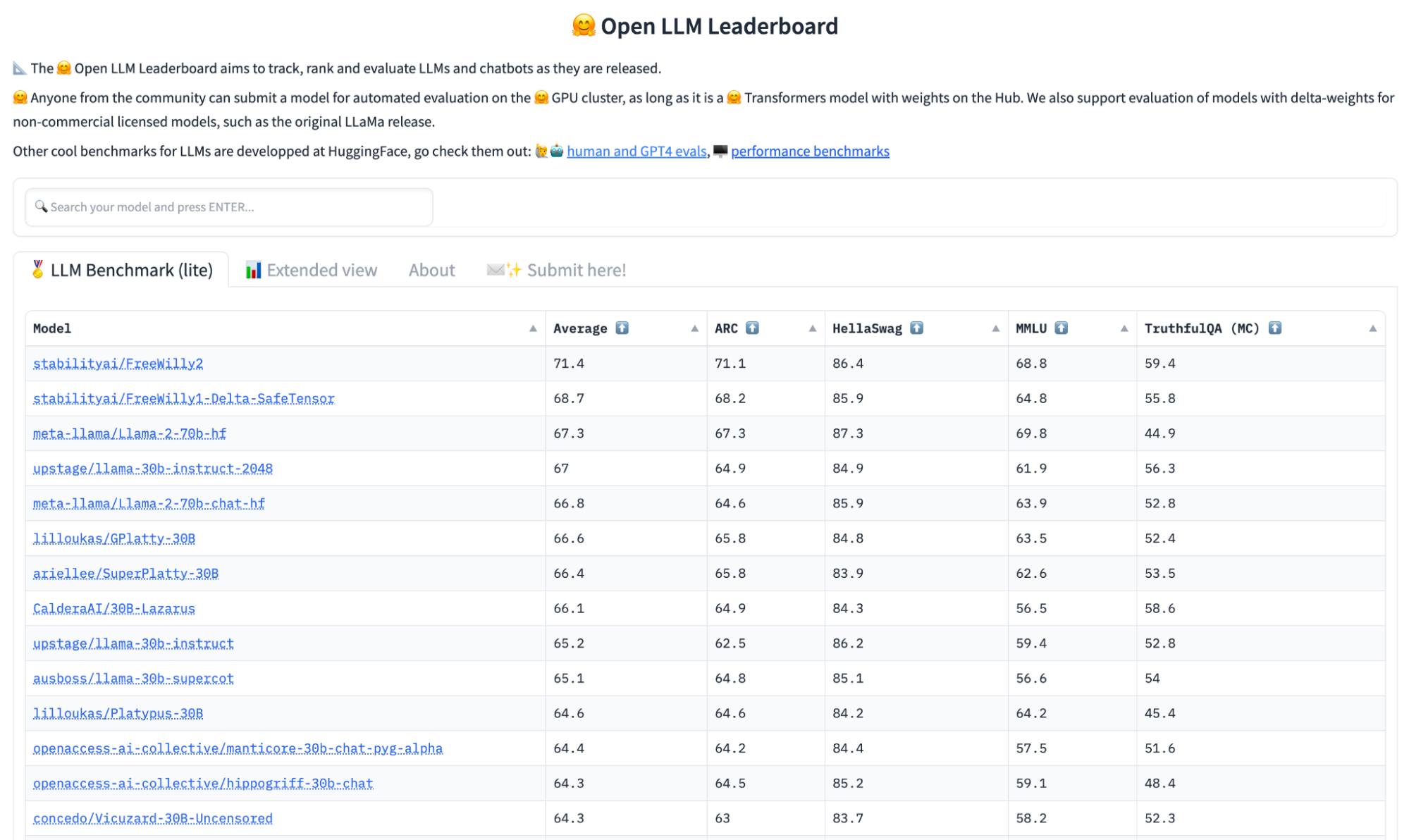 The Huggingface Open Source LLM leaderboard as of today (07/23/23)
The Huggingface Open Source LLM leaderboard as of today (07/23/23)
Stanford’s HAI maintains HELM, a very comprehensive leaderboard that evaluates models (both open source and proprietary) across many scenarios. That leaderboard is dominated by proprietary models from OpenAI, Cohere, and Anthropic (in this order). However, it does not include the latest models from either open source or proprietary sources.
 Stanford’s HAI LLM leaderboard as of today (07/23/23)
Stanford’s HAI LLM leaderboard as of today (07/23/23)
Similarly, lmsys maintains a leaderboard that includes both open source and proprietary models but is not updated so quickly as Huggingface’s. It is based on three different benchmarks and is currently dominated by GPT4 with Claude from Anthropic at a far distance (but note Claude2 is known to be much better than v1).
 LMSys LLM leaderboard as of today (07/23/23)
LMSys LLM leaderboard as of today (07/23/23)
One of the benchmarks included in the lmsys leaderboard is MMLU (multi-task language understanding), which, in its own also maintains a leaderboard where GPT4 also comes on top.
 Multi-task Language Understanding LLM leaderboard as of today (07/23/23)
Multi-task Language Understanding LLM leaderboard as of today (07/23/23)
Besides those benchmarks, every new model usually comes with its own technical report where they compare to other SOTA models. As an example, PALM-2, the new Google model used by Bard, beats GPT-4 and SOTA at most tasks:
 Palm-2 compared to SOTA and other models on different NLU tasks
Palm-2 compared to SOTA and other models on different NLU tasks
The three laws of Generative AI model evolution
So, given this immaculate track record backed by only one data point, I am going to do what people often do in this situation: turn the statements into universal laws.. These laws will stand as long as they don’t get proved wrong at some point in the future. So, please keep me honest and tell me if and when they do!
Here we go, Xavi’s three laws of GenAI model evolution:
- Best models will continue to get better in all measurable ways [2]
- Best open source models are going to be better than proprietary ones six months earlier [3]
- In the near future we will see models that are superior AND smaller than current ones. Best models in (1) will continue to grow in size.
[1] While I am writing the laws specifically thinking about LLMs these laws should apply to any GenAI model. Also, I am sure everyone would agree that LLMs are just a stepping stone to more multimodal AI models that will not only include the current text-to-image or text-to-anything, but will seamlessly integrate all modalities.
[2] There will come a time when we can’t measure any more progress because we no longer care about it (or models have become so much smarter than us that we can’t). I will leave the discussion of when that will happen out of the scope of this post. Note that
[3] One may ask if this N=6 months is a constant or it will get shorter/longer over time. My take is that this is roughly going to remain constant until we reach the “singularity” point described in [2], at which point this question won’t matter much anyways.
I hope it is clear that I am writing these laws as a way to engage in constructive discussion about what the future will bring us. I would love to hear your thoughts and feedback.
Appendix: What LLMs think of the three laws
I wrote the blog post with the help of both GPT4 and Bard. Then I asked them both what they thought the implications of the three laws were. Here are the answers:
GPT-4

Bard (Palm 2)

LlaMa 2 70B (through Perplexity.ai chat interface)


Comments